収集データを手軽に分析に利用したいみなさん、
こんにちは。ソリューションアーキテクトの伊勢です。
intdashは収集データをリアルタイムに可視化できるのが強みですが、
定時/逐次処理によるデータ分析やレポーティングのご要望もいただいています。
そこで今回は、2023年12月から新たに追加された永続化拡張機能をご紹介します。1
はじめに
永続化拡張とは
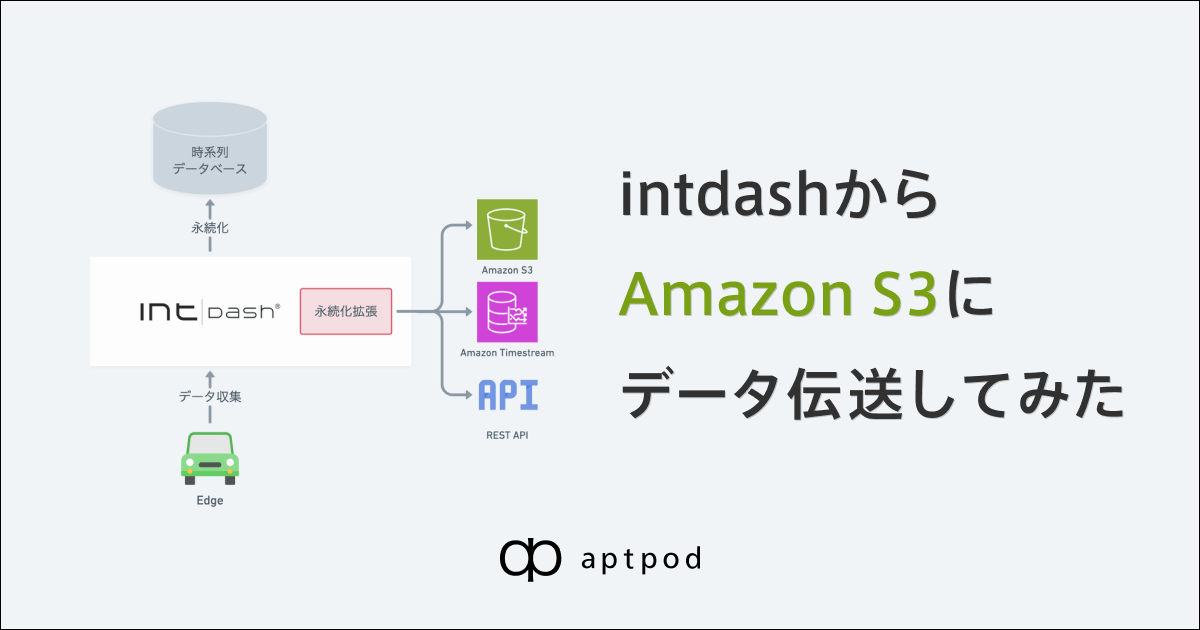
収集データをintdash内の時系列データベースに永続化すると同時に、分析基盤などの他プラットフォームにも連携します。2
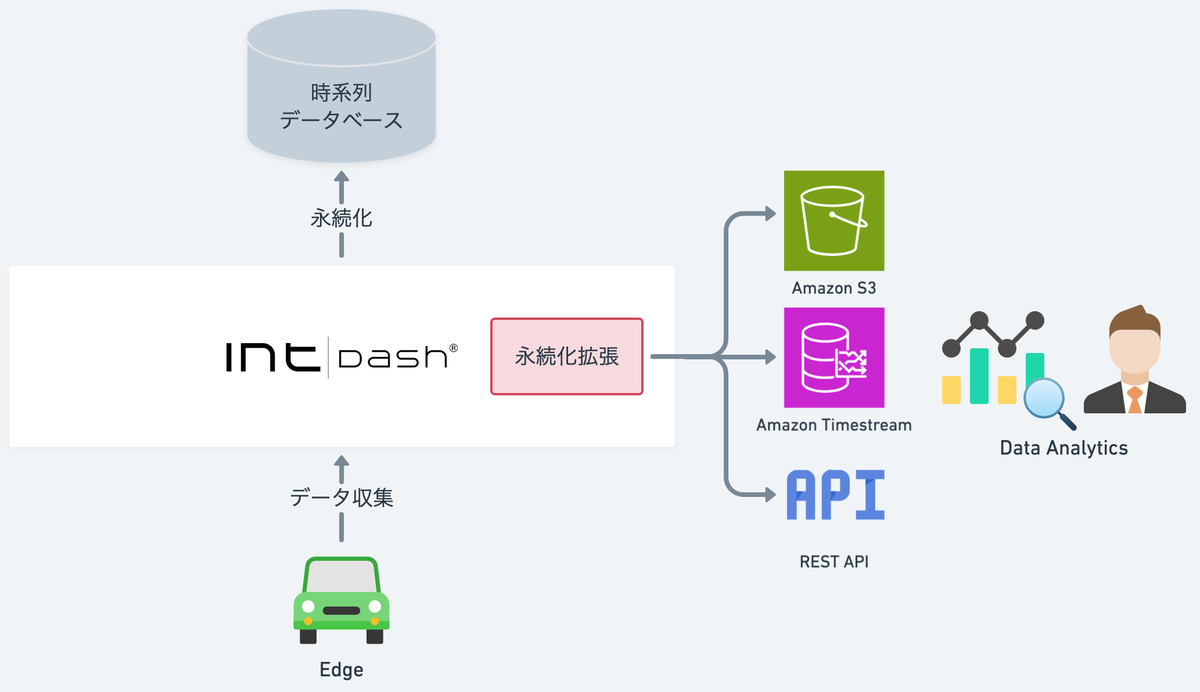
連携先には以下を選択できます。
- Amazon S3
- Amazon Timestream
- REST API
これにより、データ連携をカスタム開発せず、他プラットフォームでの収集データ利用が可能になります。
今回やること
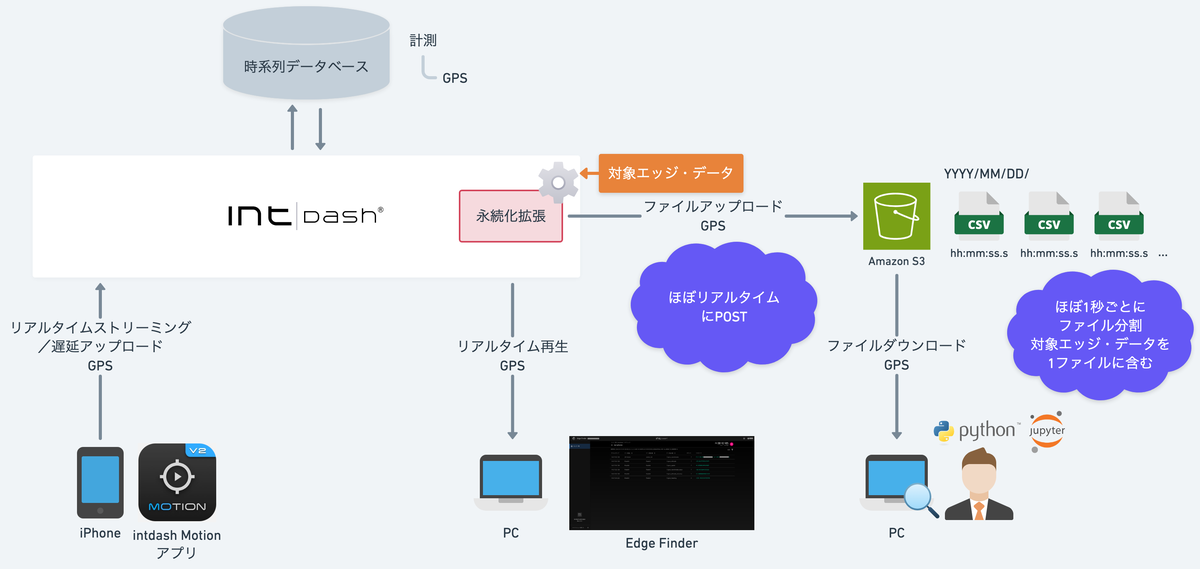
スマートフォンアプリintdash Motion V2で計測・収集したGPSデータを、intdashからAmazon S3にCSVファイルとしてほぼリアルタイムに書き出します。
計測完了後、CSVファイルをまとめてPCで取得します。
手順
S3バケットの準備
連携先となるS3のバケットを作成します。
AWSアクセスキーの準備
intdashからのアクセスに使用する、IAMでバケット所有者のAWSアクセスキーIDとシークレットアクセスキーを払い出します。
永続化拡張設定
intdashに永続化拡張を設定します。
誤って大量データ書き出しが始まらないよう、設定を作成したあとに有効化します。3
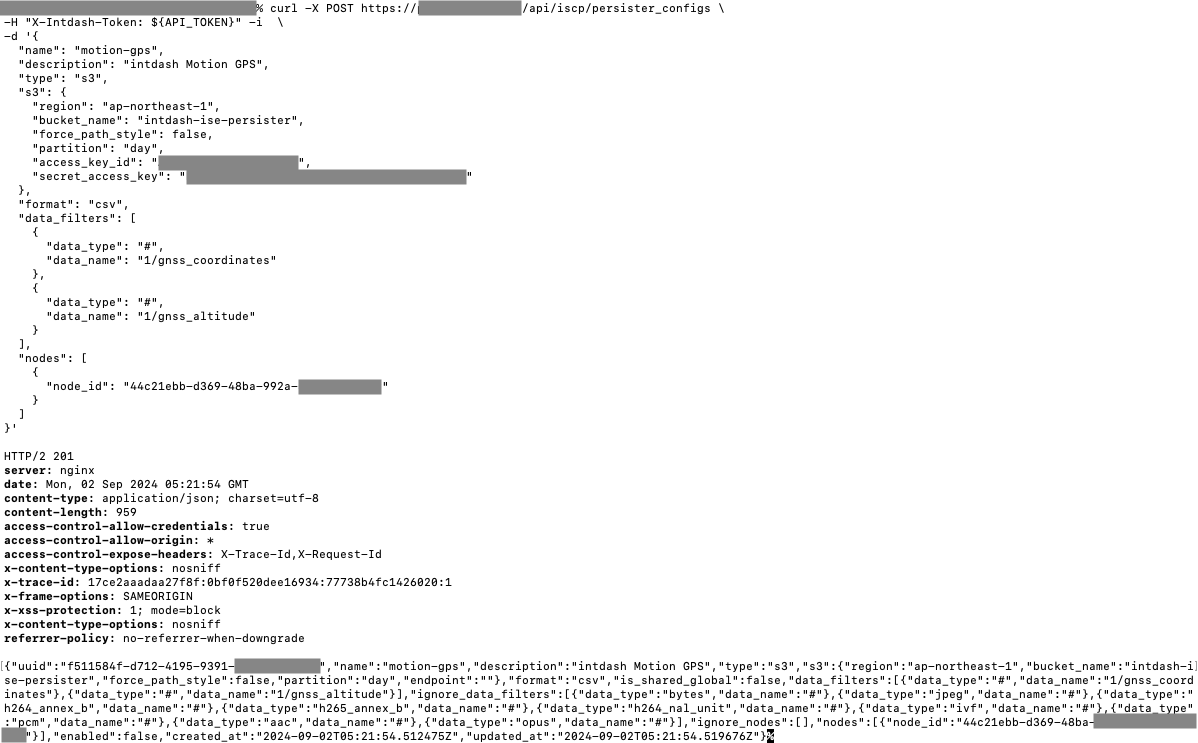
設定項目は以下の通りです。
- 設定の名前と説明
- 永続化タイプ:S3
- S3設定
- リージョン、バケット名
- パーティション単位(年、月、日)
- AWSアクセスキーID、シークレットアクセスキー
- ファイルフォーマット:CSV、JSON、RAW(Bytes)、Parquet
- 対象/除外データリスト
- データタイプ
- データ名
- iSCP 2.0のワイルドカードを利用可能
- 対象/除外ノード(エッジのUUID)リスト
- 有効/無効
作成した設定では、 対象データをGPSの2項目に制限しています。
登録された設定を確認して有効化します。
データ連携確認
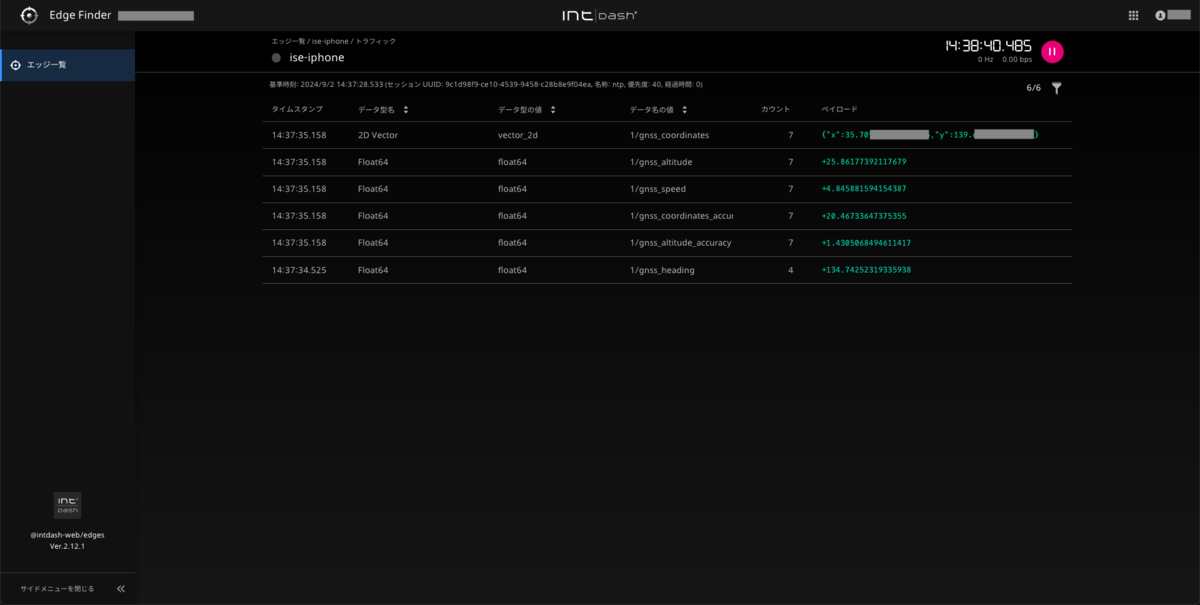
intdash Motionで計測してみます。
GPSデータの各項目がEdge Finderに表示されます。
計測を開始すると、すぐにS3バケットにCSVファイルが現れ始めます。
data-YYYY-MM-DDThh:mm:ss.sssssssssZ.csvとナノ秒単位のファイル名が付与されます。
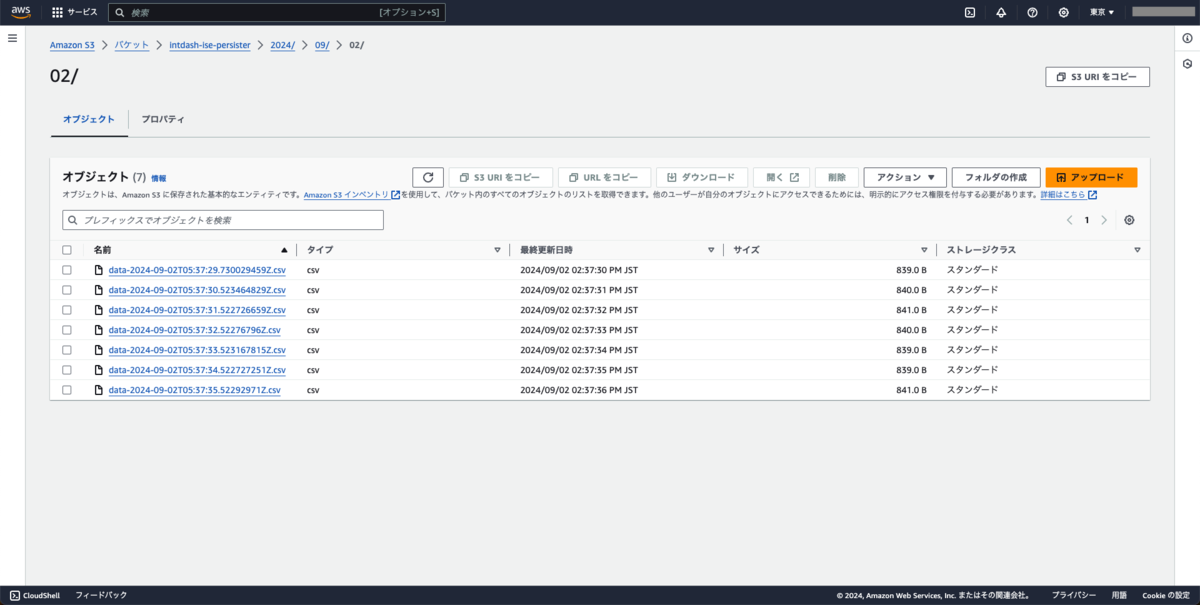
ファイルの中身はこのようになっています。
GPSデータのうち、先ほど設定した2つの対象データのみが出力されています。
- 緯度経度
1/gnss_coordinates:x, y列 - 高度
1/gnss_altitude:float列

- time:絶対時刻
- source_node_id:送信元エッジID
- session_id:計測ID
- data_type:データタイプ
- data_name:データ名称
- string, float, int, bool, x, y, z, w:値、データタイプに応じた各列に格納
- bytes:データ生値、Base64エンコード
1ファイル中には複数のエッジ・計測・データの行が混在します。
計測
移動しながら1時間ほど計測しました。
分析・レポート作成
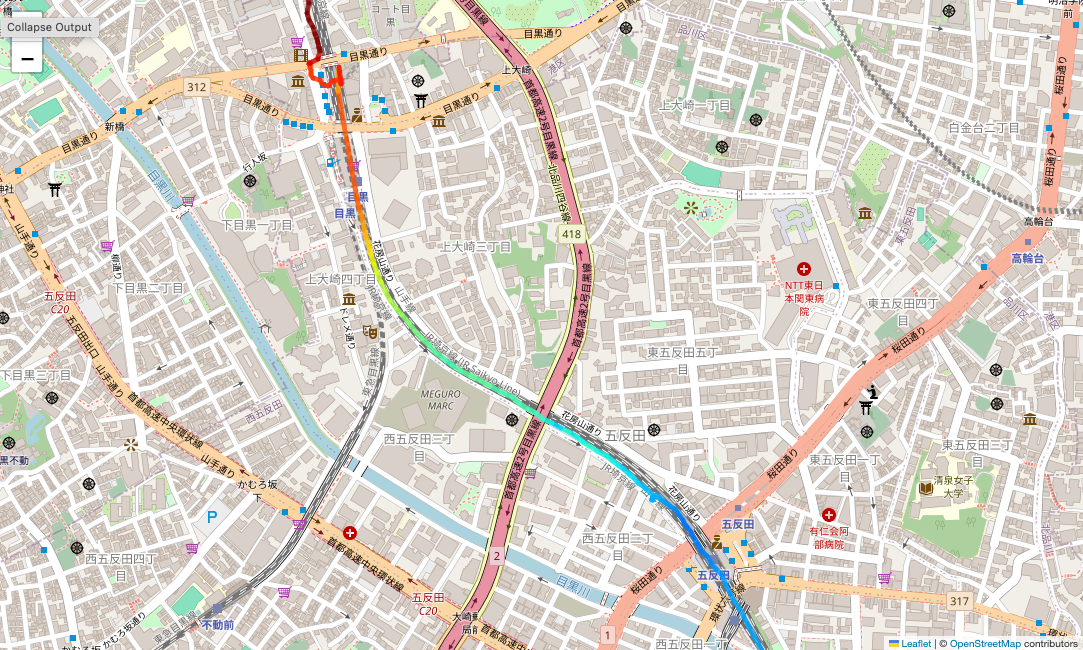
Jupyter NotebookでCSVファイルを取得して地図に表示します。4
緯度経度をつないだ線を、高度のレンジごとで色分けしています。

拡大すると1Hzで収集した緯度経度を綺麗に描けているのがわかります。
遅延アップロード
永続化拡張は、リアルタイムで送りきれなかったデータを回収する遅延アップロードにも働きます。
電波が悪い状況で試しました。

Motionに送りきれなかったデータが残っています。
手動でアップロードします。
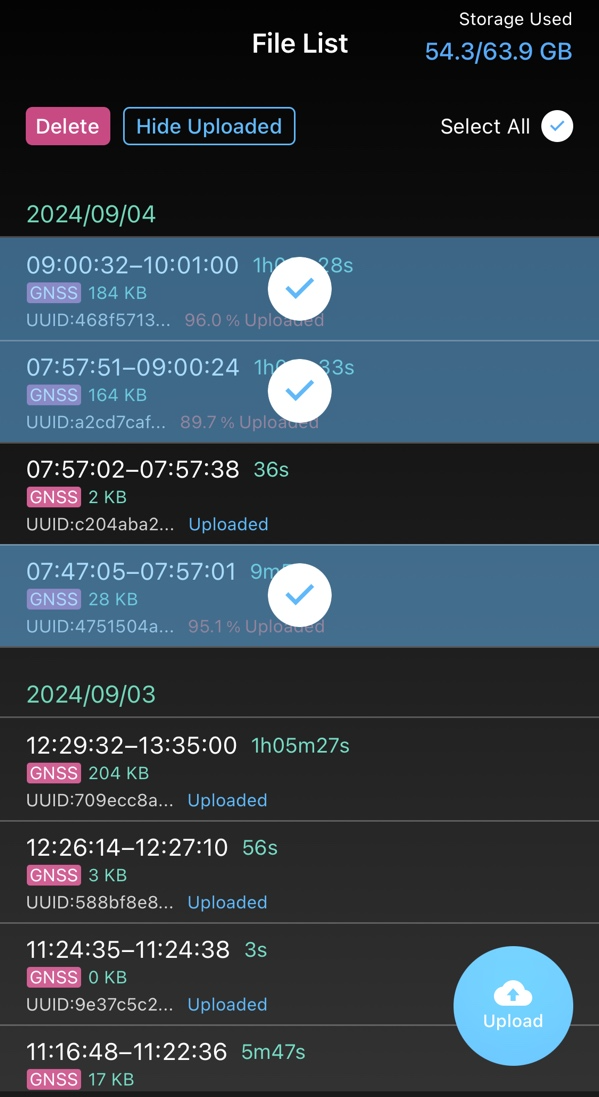

なお、エッジデバイス用のエージェントソフトウェア intdash Edge Agent なら遅延アップロードを自動で行えます。
さて、再度プロットしてみました。
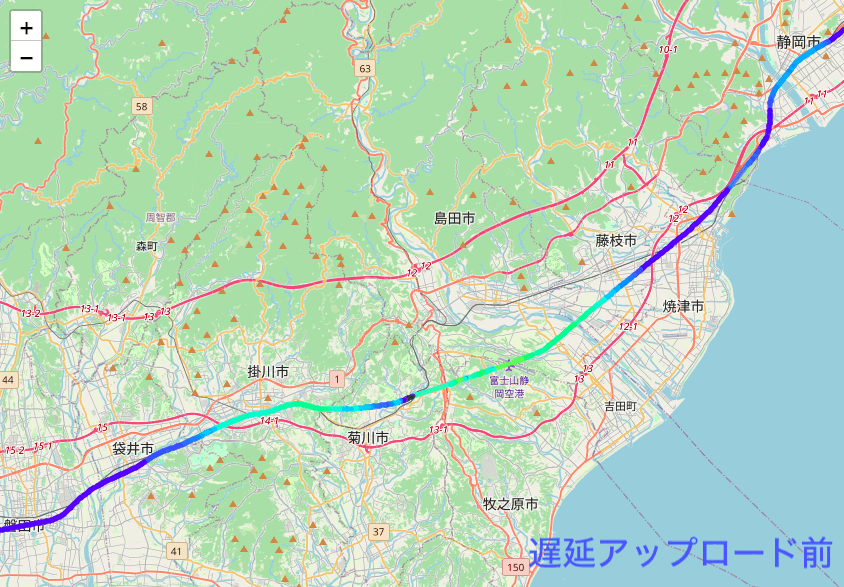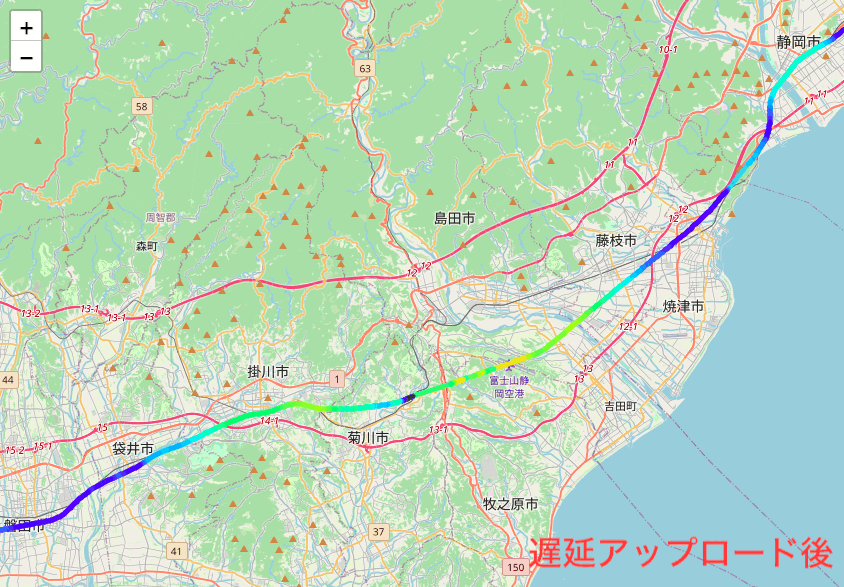
遅延アップロードで補完されたデータにより、高度のグラデーションがより精緻に表現されています。
おわりに
永続化拡張機能によって、分析のためのデータ連携の開発が不要になり、システムインテグレーションの期間・コスト低減が期待できます。
他にも、画像分析などのAI活用、他プラットフォームデータとの複合データ分析など、様々な応用が考えられます。
モビリティデータを分析基盤で活用したい方は、ぜひintdashをご検討ください。
Appendix. 分析プログラム
import boto3
import pandas as pd
import folium
from io import StringIO
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import time
# AWSアクセスキーを設定
session = boto3.Session(
aws_access_key_id='YOUR_ACCESS_KEY_ID',
aws_secret_access_key='YOUR_SECRET_ACCESS_KEY',
region_name='ap-northeast-1'
)
s3 = session.client('s3')
bucket_name = 'YOUR_BUCKET'
prefix = 'YYYY/MM/DD/' # S3オブジェクトキーパス
# ページネーションでファイルリストを取得
paginator = s3.get_paginator('list_objects_v2')
page_iterator = paginator.paginate(Bucket=bucket_name, Prefix=prefix)
file_list = []
for page in page_iterator:
for content in page.get('Contents', []):
file_list.append(content['Key'])
# バッチサイズ設定
batch_size = 100 # バッチサイズ(ファイル数)
all_coordinates_data = [] # 全ての座標データを格納するリスト
all_altitude_data = [] # 全ての高度データを格納するリスト
# カラーマップ設定
cmap = plt.get_cmap('jet') # 'jet'カラーマップを使用
norm = mcolors.Normalize(vmin=0, vmax=30)
# 地図中心設定
folium_map = folium.Map(location=[35.679889, 139.73875], zoom_start=12)
# ファイルをバッチサイズごとに処理
for batch_start in range(0, len(file_list), batch_size):
batch_files = file_list[batch_start:batch_start + batch_size]
# バッチ処理
for file_key in sorted(batch_files):
try:
csv_obj = s3.get_object(Bucket=bucket_name, Key=file_key)
body = csv_obj['Body'].read().decode('utf-8')
df = pd.read_csv(StringIO(body), usecols=['time', 'data_name', 'x', 'y', 'float'])
# 緯度経度データ抽出
coords_df = df[df['data_name'] == '1/gnss_coordinates'][['time', 'x', 'y']]
# 高度データ抽出
alt_df = df[df['data_name'] == '1/gnss_altitude'][['time', 'float']]
all_coordinates_data.extend(coords_df.values.tolist())
all_altitude_data.extend(alt_df.values.tolist())
except Exception as e:
print(f"Error reading {file_key}: {e}")
# S3 API制限回避
time.sleep(2) # スリープ
# DataFrameに変換してソート
coordinates_df = pd.DataFrame(all_coordinates_data, columns=['time', 'x', 'y'])
altitude_df = pd.DataFrame(all_altitude_data, columns=['time', 'altitude'])
# timeでソート
coordinates_df.sort_values('time', inplace=True)
altitude_df.sort_values('time', inplace=True)
# 緯度(x)と経度(y)を地図にプロット
for i in range(len(coordinates_df) - 1):
# 現在のポイントと次のポイントのデータ
row_current = coordinates_df.iloc[i]
row_next = coordinates_df.iloc[i + 1]
# 高度の行をtimeで検索
altitude_row_current = altitude_df[altitude_df['time'] == row_current['time']]
altitude_current = altitude_row_current['altitude'].values[0] if not altitude_row_current.empty else None
# 色の設定
if altitude_current is not None:
color = mcolors.to_hex(cmap(norm(altitude_current)))
else:
color = 'gray'
# ポリラインを描画
folium.PolyLine(
locations=[(row_current['x'], row_current['y']), (row_next['x'], row_next['y'])],
weight=5,
opacity=0.8,
color=color
).add_to(folium_map)
# 地図表示
folium_map.save('map.html')
folium_map