
こんにちは。テクニカルライターの篠崎です。 aptpod Advent Calendar 2025 の12月24日の記事を担当します。
今年も生成AIの話題を見聞きしない日はありませんでした。
製品ドキュメントの制作を担当している私も、日々の業務にAIを活用する可能性を模索してきました。
例えば、AIに資料を渡して文章を生成してもらったり、見本に沿って書き直してもらったり、テキストを処理するスクリプトを書いてもらったり、いろいろなことをやっています。
しかし、うまくいくこともあればいかないこともあり、期待通りにならない場合は「これは自分の指示の仕方が悪かったのだろうか、または、このような作業は現時点ではAIには向いていないのだろうか」と考え込んでしまうこともあります。
そんななかで、簡単なのに常に効果が見込めるものが1つあったので、それをご紹介します。 それは、誤字脱字の発見、校正です。
補足: 以下でご紹介するのは、「使い方の一例」です。これが最良の校正方法ということではありません。 また、今後のAIツールの進展により使い方は変わっていくことと思います。
本記事で対象にするドキュメント
私は弊社製品のドキュメントの制作を担当していますので、それを例にして説明します。
製品ドキュメントは、 Sphinx というツールで作成しています*1。
原稿はテキストファイル(reStructuredText記法)です。ソフトウェアのコードと同じように、Gitで管理しています。
この原稿をSphinxでHTML形式にビルドすることで、ユーザー向けのドキュメントサイトを作っています。
もちろん、制作時には何度も読み返しますし、必要に応じてAI以外の校正ツールも使いますが、それでも後から誤字や脱字に気づくことはあります。 こういった誤字脱字を見つけるのにAIが使えないかと思い、やってみることにしました。
Claude Codeを使ってみる
AIを使って校正するのに最も簡単な方法としては、ChatGPTなどLLMベースのチャットボットの画面に原稿をペーストして(または原稿をアップロードして)、「誤字脱字がないか確認してください」と指示する、という方法が思いつきます。これはすぐにできますし、十分に役に立ちます。
でも、コピー&ペーストやアップロードをせずに校正したいと考え、コマンドラインベースのAIコーディングツール Claude Code を使うことにしました (Claude Code以外の類似ツールでも良いのですが、身近に使えるのがこれだったのでまずはこれでやってみました)。
Claude Codeのプロンプト上で「features/index.rstに誤字脱字がないか確認してください。」のようにファイル名を明示して指示するだけで、誤字脱字を見つけて修正してもらえます(.rst は原稿reStructuredTextファイルの拡張子です)。
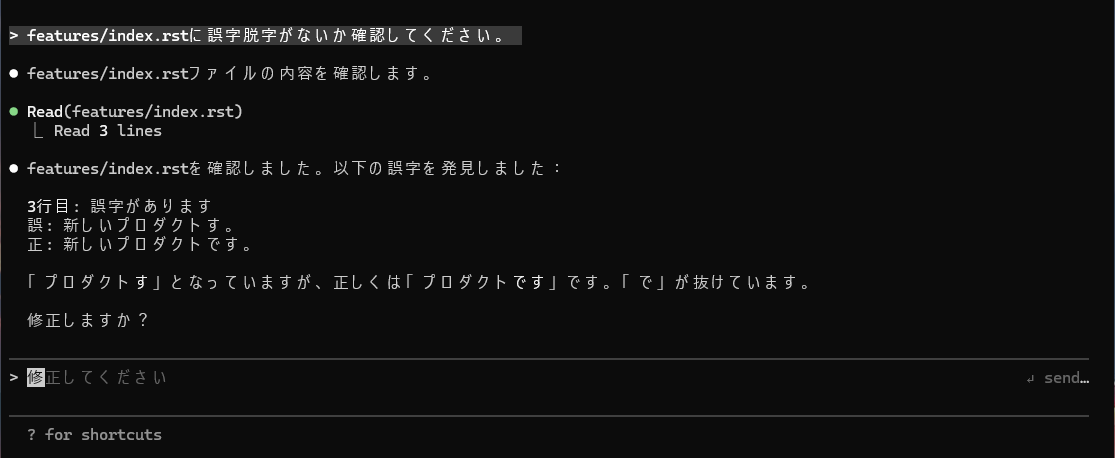
実際には、もうすこし詳しい指示をしたいですし、また、いつも一定の指示を簡単に行いたいです。 このような場合にカスタムコマンドという機能が便利でした。
カスタムコマンドを設定してみる
カスタムコマンドは、あるひとかたまりの指示に名前を付けたものです。
/ に続けてその名前(コマンド名)を入力することで、実行できます。
プロジェクト用のカスタムコマンドは、 .claude/commands/ で定義します。
例えば、以下のように定義します(この定義自体も、Claude Codeと相談しながら作りました)。
ファイル名: .claude/commands/proofread.md
# /proofread コマンド ## 概要 指定されたディレクトリまたはファイル内の*.rstファイルについて、 タイポや書式エラーを体系的にチェックし修正するコマンドです。 コードではなく自然言語を扱います。 ## 使用方法 ``` /proofread <$ARGUMENTS(ディレクトリまたはファイル名)> ``` 例: - `/proofread apps` - appsディレクトリ内の全.rstファイルをチェック - `/proofread my-app/tutorials/index.rst` - 特定ファイルをチェック ## 処理手順 ### 0. ARGUMENTSの確認 $ARGUMENTSの指定がない場合、「/proofreadコマンドに続けて、 対象のディレクトリまたはファイルを指定してください。」と表示して終了します。 ### 1. チェック 修正の判断基準は以下の通りです。 #### 必ず修正すべきもの 1. **明確な誤字・脱字・スペルミス** - 文字の欠落、誤った文字 - 例:「こ方法」→「この方法」、「データをの保存」→「データの保存」 2. **文法的に明らかな誤り** - 助詞の誤用(文意が通じない場合のみ) - 主語述語の不一致 3. **技術的な誤り** - 単位表記の誤り - 例:「KG」→「kg」、「GByte」→「GB」 - 用語の明らかな誤用 #### 修正してはいけないもの 1. **reStructuredTextの形式は修正しない(ビルドエラーにならない限り現状維持)** - バッククォートの前後のスペースは修正しない - タイトル下線の長さは修正しない - toctreeの記法は修正しない - セクション見出しの記号の選択や数は修正しない 2. **表現上の軽微な問題は修正しない** - コロンの有無は修正しない - 文末表現の微調整はしない - 括弧の前後のスペースは修正しない 3. **構造は修正しない** - 見出しレベルの修正はしない - セクション構造の再編成はしない - ディレクティブの種類は修正しない 4. **その他修正不要なもの** - 「読みやすくなる」程度の改善はしない - 読点の位置は修正しない - 全角文字と半角文字の間のスペースの有無は修正しない - 長音符号の有無は修正しない - リンクlabel(例: `.. _my-reference-label:` )のスペルミスは修正しない ### 2. ログの記録 **1ファイルのチェックが終わるごとに、以下のコマンドを実行する** ```bash echo "チェックしたファイルのパス" >> proofread-log.txt ``` これによりログが記録されます。 ### 注意 **迅速化は行わない** - 効率化やパターン認識による省略は行わない - 全ファイルの全ての行を同じレベルの注意深さでチェックする - 間違いには傾向がないかもしれないため、先入観を持たずに全体を見る **1ファイルのみ処理** - 指定された1ファイルを完全に読み込み、内容を理解してチェックする **見落とし防止** - 「よくあるパターン」に頼らず、各行を個別に検証 - 技術的な文脈を理解してからタイポを判断 - 不明な点があれば、関連ファイルや前後の文脈を確認
最後の「注意」のところで、「迅速化は行わない」ことをしつこく書いています。
このような指示をしないと、多数のファイルを対象にした場合、「それまでに見つかった間違いをもとに、それと似た間違いがないか」の検索が始まることがありました。 例えば、助詞「の」が重複した「のの」を発見した後は、助詞の重複がないかを検索し、それがなければ問題なしとする、といった動きをしているように見えました。
しかし、ここではすべての行を念入りに確認してほしかったので、このようにしています。*2
実行する
これにより、例えば以下のようなコマンドで、校正が始まります。
# featuresディレクトリ内を校正 /proofread features
実行中、ファイルの書き換えやシェルコマンド実行については、実行してよいか確認があります(設定によります)。私は普段は原稿ファイルの書き換えは確認なしに行ってもらうようにしています。
そのうえで、完了後に修正結果を git diff で確認します。意図しない修正が行われているのを見つけたら、その部分だけリバートします。
確認してリバートするのは手間ですので、できるだけ、意図しない修正が発生するのを抑えたいですが、完全に抑えることはできていません。 どれだけ抑えられるかは、カスタムコマンドの定義次第かと思いますので、まだ工夫のしどころがありそうだと思っています。
効果
意図的に誤字脱字や間違いを含んだファイルを作ってテストしてみると、以下のような間違いを見つけることができました。
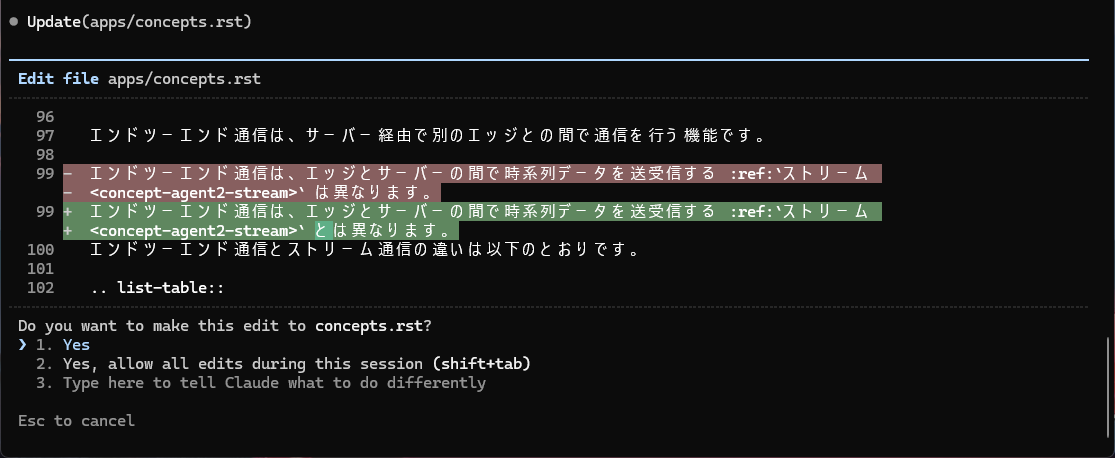
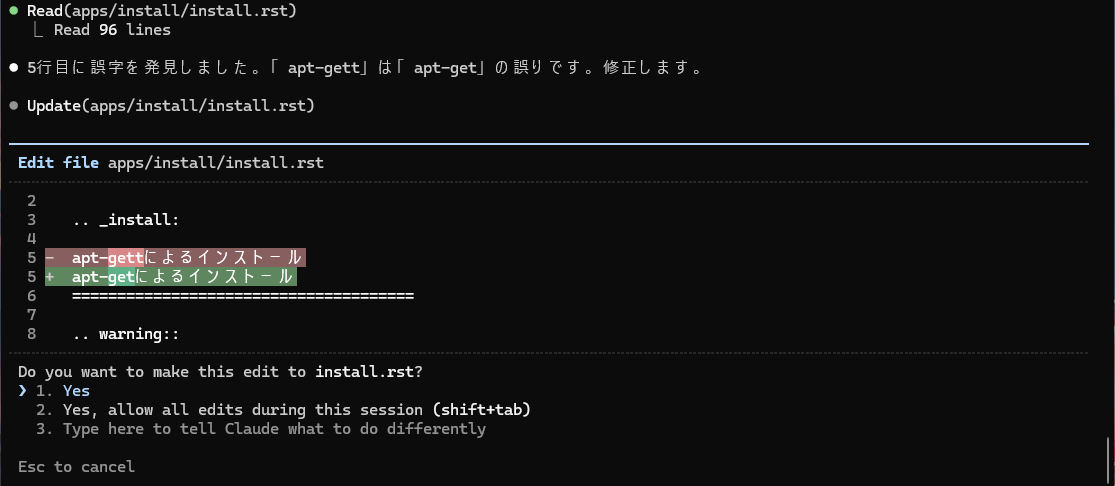
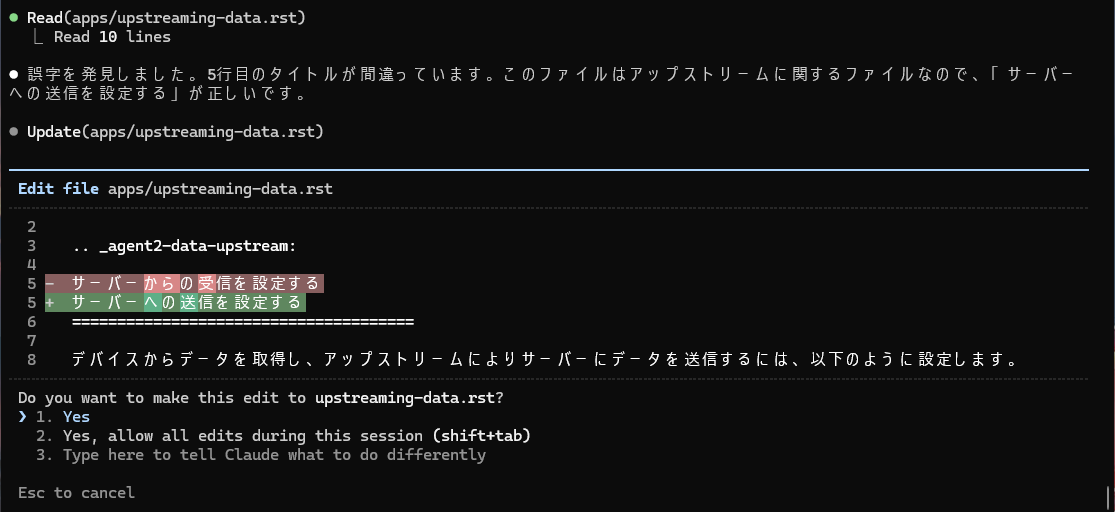
特に最後に挙げた例は、単純な誤字脱字の修正ではなく、「送信について説明している箇所なのに、見出しが『受信』になっている」という指摘です。
なお、何度か試してみると、そのときごとに違う指摘になる場合があるので、いつもすべての間違いを見つけてくれるわけではないようです。
まとめ
上記のように、単純な誤字脱字のほかに、なかなか見つけにくい間違いまでも見つけてくれました。 これにより、ドキュメント公開前に「助かった!」という経験を何度かしました。
上に挙げたカスタムコマンド定義を見ていただけると分かるとおり、それほど特別なことを指示しているわけではないですが、このような準備をしておくだけでいつでも簡単に校正できます。独自ルールもほとんど入れていませんので、汎用的に使えます。
ただし、それなりにトークン消費があるので、大量のドキュメントを校正するときには注意が必要です。 そして、いつもすべての間違いを見つけてくれるわけではないので、過信はできません。
紹介は以上です。
ライターは十分に注意深く執筆しなければならないのはもちろんですが、自分のほかにもうひとり、いつでもすぐに原稿を読み返してくれるAIのアシスタントがいるというのは、ありがたいことだと思っています。
*1:Sphinxは、HTMLもPDFも出力できて、カスタマイズ方法が豊富なのが魅力です。以前に本ブログでもご紹介しました: