
みなさまこんにちは。先進技術調査グループのキシダです。私自身は4つめの記事投稿となりました。ネタ切れ感が否めないですが、前回に引き続き音声データにまつわるテーマをご紹介したいと思います。
さて突然ですが、最近AWSが展開している注目の機械学習サービス「Amazon SageMaker」に関連した記事をよく見かけるようになりました。さらには今年の初旬あたりに Amazon SageMaker Studioなど多数のサービスが発表され、より盛り上がりをみせています。
一方で、私自身は「音声解析」系の技術検証をひっそり行っており、ふと「今話題となっているAmazon SageMakerで音声分類アルゴリズムがサクッと作れたりしないかな?」と思い立ったので、実際に試してみました。
検証のアプローチ
本検証には複数のステップを盛り込んでいるので、以下のアプローチに関心がある方はそのまま読み進めていただければと思います。
モデルのアルゴリズム部分は「組み込み(build-in)アルゴリズム」を使用する
Amazon SageMakerには「組み込み(build-in)アルゴリズム」と言われる、実装されたモデルのアルゴリズムが数種類あります。こちらを使用するとモデルのアルゴリズム部分を実装することなく手軽に試せます。
今回は「イメージ分類アルゴリズム」を使用します。
音声は「スペクトログラム」に変換し画像分類にかける
今回は音声の分類機能を作りたいため、音声の特徴量を画像で表現し、その画像を画像分類モデルにかけてみたいと思います。
音声の特徴量を画像で表現するものとして、「スペクトログラム」という形式がよく用いられるのでこちらを使用します。スペクトログラムとは、3次元(時間、周波数、音圧)の特徴量をグラフで表現するもので、視覚的に音声の特徴を捉えることが可能です。
音声からスペクトログラムに変換して分類するアプローチは以下を参考にしています。
Amazon SageMakerのハイパーパラメータ調整ジョブを使用して精度を向上させる
「ハイパーパラメータ調整ジョブ」とは、指定の範囲内で多数のハイパーパラメータを自動的に作成し、複数のトレーニングジョブを実行してくれるジョブです。すべてのジョブが完了すると、指定した指標に対して最も成績がよかったモデルを採用し、結果をレポートしてくれます。
私自身こちらを試したことがなかったので、これを機会にこのサービスも試してみました。
実際にためしてみる
使用するデータをさがす
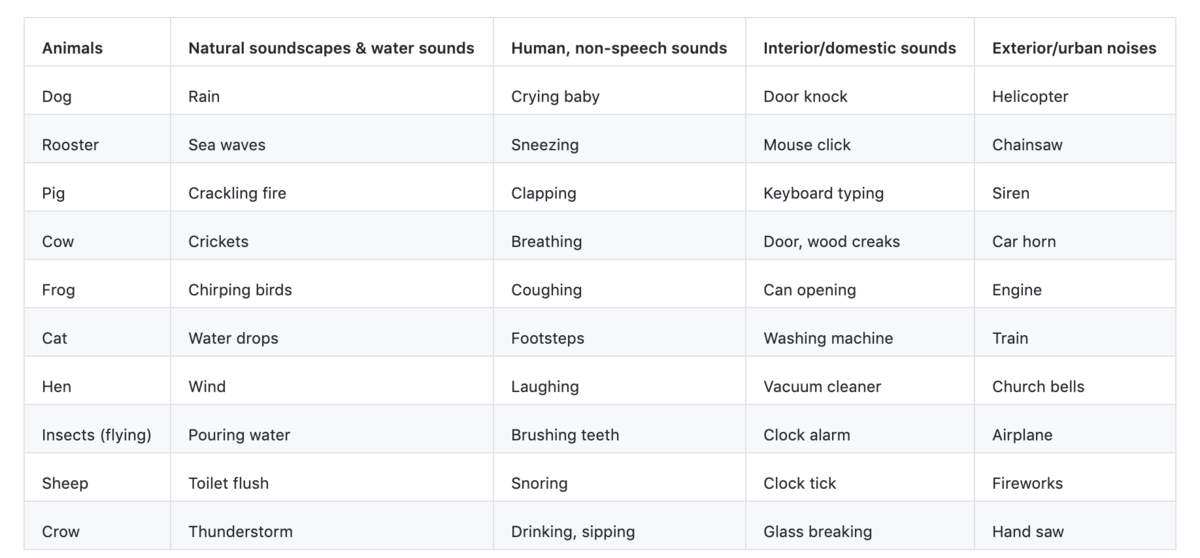
今回はユースケース自体を固めず、適当なサンプルデータで検証します。音声分類でよく使用されているサンプルである、ESC-50 という50種類の音声データを使用します。
GitHub - karolpiczak/ESC-50: ESC-50: Dataset for Environmental Sound Classification
音声からスペクトログラムに表現する
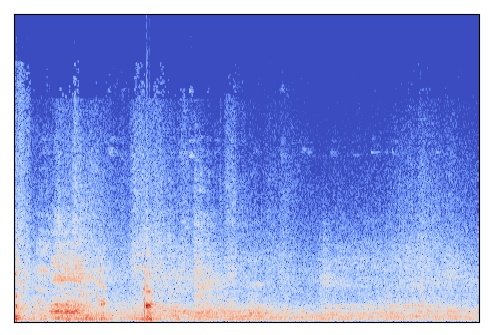
まずは音声を画像分類アルゴリズムに与えるために、スペクトログラムに変換していきます。
変換を行うためのライブラリもいくつかあるのですが、今回は librosa というライブラリを使います。
# change wave data to stft def calculate_sp(x, n_fft=512, hop_length=256): stft = librosa.stft(x, n_fft=n_fft, hop_length=hop_length) sp = librosa.amplitude_to_db(np.abs(stft)) return sp # display wave in spectrogram def show_sp(sp, fs, hop_length): librosa.display.specshow(sp, hop_length=None)
すると、以下のようにスペクトログラムが出力されます。
データセットを作成する
変換するだけだと簡単なのですが、サンプルのデータをそのまま使うと2000データほどしかないので、トレーニングデータをもう少し増やします。サンプル数2000枚のうち、500枚をテストデータ、1500枚を訓練データに分け、訓練データをさらに以下のように加工することで6000枚に増やします。
元のデータのスペクトログラム
ホワイトノイズをかける
#data augmentation: add white noise def add_white_noise(x, rate=0.002): return x + rate*np.random.randn(len(x))
フレームをずらす
# data augmentation: shift sound in timeframe def shift_sound(x, rate=2): return np.roll(x, int(len(x)//rate))
伸縮する
# data augmentation: stretch sound def stretch_sound(x, rate=1.1): input_length = len(x) x = librosa.effects.time_stretch(x, rate) if len(x)>input_length: return x[:input_length] else: return np.pad(x, (0, max(0, input_length - len(x))), "constant")
これである程度のデータ量を作成することができました。
今回はトレーニング時にS3に保存されているデータセットを参照する方式にするので、上記をS3にアップロードして完了です。
次に上記の画像に対して、正解データ(メタ情報)を示したファイルを作成します。 音声に紐づくclassについては、以下のcsvファイルに記載されているのでこちらを参照します。
ESC-50/esc50.csv at master · karolpiczak/ESC-50 · GitHub
Amazon SageMakerで扱うメタ情報のファイル形式の1つに、 manifest 形式 という形式があります。今回はこのフォーマットに従い、上記のcsvファイルをmanifestファイルに変換しておきます。
作成したmanifestファイルの一部を以下に記載しておきます。
{"source-ref":"s3://sagemaker-audio-classification/rawdata/ESC-50/validation/2-122104-B-0-0.jpg","class":"0","class-metadata":{"class-name":"dog"}}
{"source-ref":"s3://sagemaker-audio-classification/rawdata/ESC-50/validation/4-183992-A-0-0.jpg","class":"0","class-metadata":{"class-name":"dog"}}
{"source-ref":"s3://sagemaker-audio-classification/rawdata/ESC-50/validation/4-164021-A-1-0.jpg","class":"1","class-metadata":{"class-name":"rooster"}}
{"source-ref":"s3://sagemaker-audio-classification/rawdata/ESC-50/validation/4-164064-B-1-0.jpg","class":"1","class-metadata":{"class-name":"rooster"}}
こちらもS3にアップロードしておきます。
Amazon SageMakerでトレーニングする
それでは、実際にトレーニングを行っていきます。 Amazon SageMaker Python SDK を使用してトレーニングを進めていきます。
まずは 画像分類アルゴリズムを表す image-classification のコンテナイメージを取得します。
from sagemaker.amazon.amazon_estimator import get_image_uri training_image = get_image_uri(sess.boto_region_name, 'image-classification', repo_version="latest")
Estimatorを生成して、hyperparameterを設定します。
ic = sagemaker.estimator.Estimator(training_image,
role,
train_instance_count=1,
train_instance_type='ml.p2.xlarge',
train_volume_size = 50,
train_max_run = 360000,
input_mode= 'Pipe',
output_path=s3_output_location,
sagemaker_session=sess)
ic.set_hyperparameters(
num_layers=50,
image_shape = "3,224,224",
num_classes=50,
num_training_samples=6000,
mini_batch_size=32,
epochs=30,
learning_rate=0.1,
top_k=2)
先程作成したデータを指定し、トレーニングを開始します。
train_data = sagemaker.session.s3_input(
s3train,
distribution='FullyReplicated',
content_type='application/x-recordio',
record_wrapping='RecordIO',
s3_data_type='AugmentedManifestFile',
attribute_names=['source-ref', 'class'],
shuffle_config= sagemaker.session.ShuffleConfig(seed=1234)
)
validation_data = sagemaker.session.s3_input(
s3validation,
distribution='FullyReplicated',
content_type='application/x-recordio',
record_wrapping='RecordIO',
s3_data_type='AugmentedManifestFile',
attribute_names=['source-ref', 'class']
)
data_channels = {'train': train_data, 'validation': validation_data}
ic.fit(inputs=data_channels, logs=False)
以下のログが出力され、完了したことを確認します。
2020-01-29 07:06:15 Starting - Starting the training job 2020-01-29 07:06:17 Starting - Launching requested ML instances................. 2020-01-29 07:07:48 Starting - Preparing the instances for training................... 2020-01-29 07:09:30 Downloading - Downloading input data.. 2020-01-29 07:09:47 Training - Downloading the training image........... 2020-01-29 07:10:47 Training - Training image download completed. Training in progress............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................... 2020-01-29 08:16:27 Uploading - Uploading generated training model... 2020-01-29 08:16:49 Completed - Training job completed
コンソール上でも完了していることが確認できます。
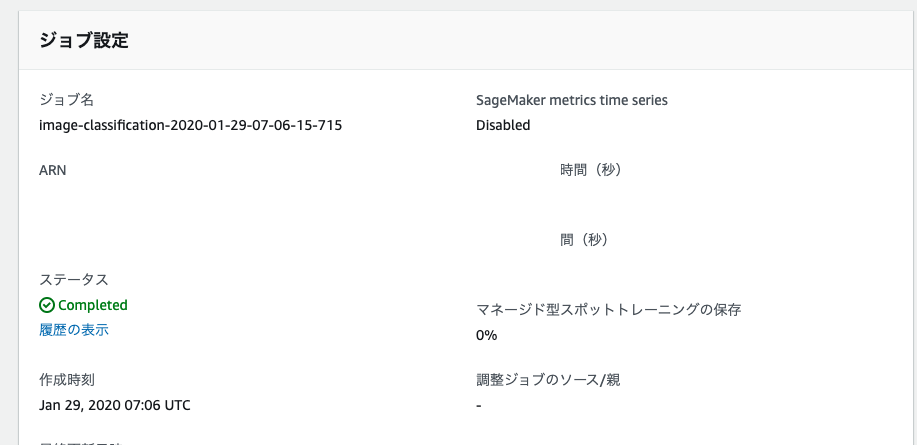
しかしながら、ログの結果を見てみると、validationデータに対しての正答率が 0.04 と著しく低く、これでは使い物になりません。
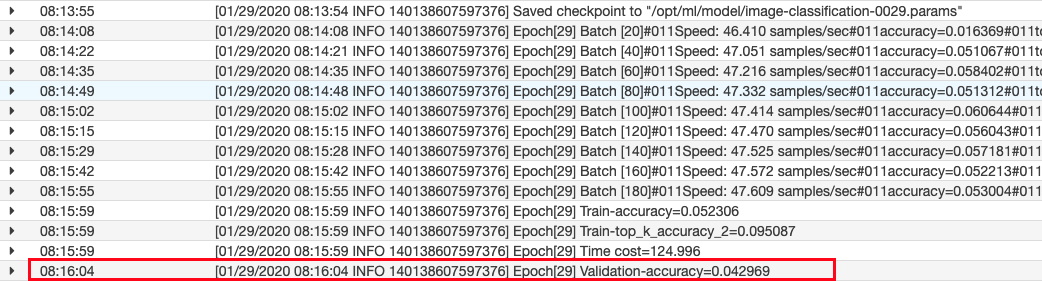
そのため、Amazon SageMakerの「ハイパーパラメータ調整ジョブ」を使用して、より精度の高いモデルの作成にチャレンジしてみます。
ハイパーパラメータ調整ジョブを使用して精度向上を試みる
今までは1通りのパラメータでしか実行していなかったので、このサービスを使って複数のトレーニングジョブを一度に実行したいと思います。
まずはハイパーパラメータの調整範囲を指定します。
hyperparameter_ranges = {
'learning_rate': sagemaker.parameter.ContinuousParameter(min_value=0.0001, max_value=0.005, scaling_type='Auto'),
'optimizer':sagemaker.parameter.CategoricalParameter(['sgd', 'adam', 'rmsprop', 'nag']),
'mini_batch_size': sagemaker.parameter.IntegerParameter(min_value=20, max_value=100, scaling_type='Auto'),
}
HypterparameterTunerを生成します。
tuner = sagemaker.tuner.HyperparameterTuner(
estimator=ic,
objective_metric_name='validation:accuracy',
hyperparameter_ranges=hyperparameter_ranges,
objective_type='Maximize',
max_parallel_jobs=1,
max_jobs=30,
base_tuning_job_name='audio-classification',
tags=[
{
'Key':'Project',
'Value':'demo'
}
]
)
ジョブを開始します。
tuner.fit(inputs=data_channels, logs=False)
ジョブが完了すると、コンソール上の「最善のトレーニングジョブ」から、先程 objective_metric_name で指定した指標に対して最も成績が良く出たトレーニングジョブを確認できます。
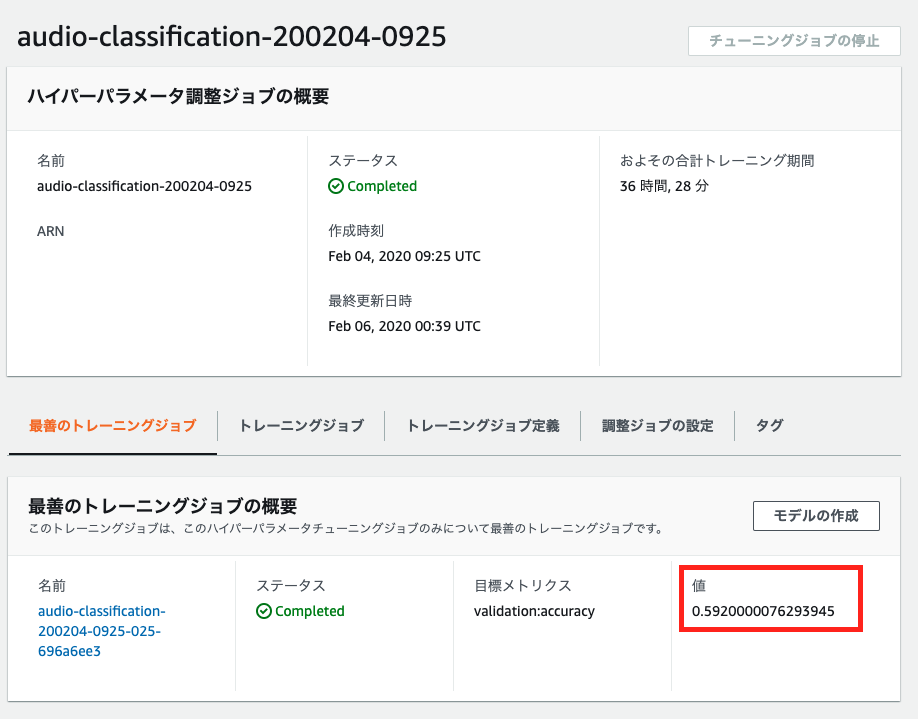
右下の赤枠に着目すると、最終的に精度が6割弱まであがったことが確認できました!
実際にモデルを使用して推論してみる
せっかくモデルが作成できたので実際に推論させてみます。試しに「拍手」の音をモデルに与えて、その判定結果を見てみましょう。
import json image_key = '{}/training/1-105224-A-22-0.jpg'.format('rawdata/ESC-50') object = s3.Object(bucket_name, image_key) response = object.get() body = response['Body'].read() classification.content_type = 'image/jpeg' results = classification.predict(body) detections = json.loads(results)
返ってきた結果を確認します。
import numpy as np max_arg = np.array(detections).argmax() max_score = np.array(detections).max() print('result class: {} score: {}'.format(class_dict[max_arg], max_score) )
実行すると・・・
result class: clapping score: 0.948319673538208
見事に正解していました!確信度も高い値となっています。
まとめ
今回の検証をまとめると、以下の通りとなりました。
音声データと画像分類モデルの親和性の評価
☺️ 正解率は60%
☺️ 特に変わった前処理も行わずこの精度が出るため、親和性が高いと言えるのではAmazon SageMakerの「画像分類アルゴリズム」の使いやすさ
☺️ ベースのトレーニングモデルを使用できるなど、精度を手軽に上げるサポートありAmazon SageMakerのハイパーパラメータ調整ジョブの使いやすさ
☺️ 自動であらゆる種類のパラメータを組み合わせて検証してくれるのは便利。組み合わせ方のアルゴリズムも指定できる
概ね好感触という結果になりました🎉
最後に
今回は音声データをAmazon SageMakerの組み込みアルゴリズムで自動分類できないか検証してみました。
私自身は音声関連の記事ばかり投稿していますが、先進技術調査グループでは他にもロボティクスや機械学習に関連したテーマなど、様々な技術テーマに沿って調査・検証をすすめております。これから投稿される記事も内容の濃いものになると思うので、引き続きwatchいただければと思います!
それでは、ご覧いただきありがとうございました!