
みなさまこんにちは。プロダクト開発本部の岸田です。
以前に「ハードウェア側に機械学習環境を立てて推論を行い、クラウドに結果を収集して分析状況を確認する」ユースケースをこちらの記事で考察しました。手軽にローカルデバイスとクラウドを連携するサービスとして有名なものが「AWS IoT Greengrass」ですよね。公式のドキュメントでもエッジ推論システムをAWS IoT Greengrassで構築するユースケースが紹介されています。
そこで上記を参考に、弊社の製品であるJetson TX2搭載のEDGEPLANT T1を利用して、AWSサービスを活用したエッジ推論システムをつくってみたいと思います!
- この記事の対象読者
- EDGEPLANT T1 で手軽にエッジ推論を構築するメリット
- 今回のゴール
- 実際に構築してみる
- モデルをAmazon SageMakerを用いてコンパイル
- EDGEPLANT T1で機械学習環境を構築する
- EDGEPLANT T1にAWS IoT Greengrassをインストールする
- 推論を行うコードをLambdaとしてデプロイする
- LambdaをGreengrass Groupに追加する
- SageMakerでコンパイルしたモデルをGreengrass Groupに追加する
- 推論実行用のローカルデバイスをGreengrass Groupに追加する
- サブスクリプションを定義する
- デプロイパッケージをテストする
- IoT Analytics にデータセットをためる
- QuickSightでダッシュボードを作り結果を確認する
- まとめ
この記事の対象読者
NVIDIA提供のJetsonシリーズの機器上で、上記の公式ドキュメントのようなことがやりたい方
Jetson TX2を扱う場合は、JetPackの依存関係などを考慮しながら適切に進める必要があり、いくつか考慮すべきポイントがあります。本記事ではその点をいくつかまとめてます。
EDGEPLANT T1を単体で購入いただいている方
EDGEPLANT T1をつかって簡単な機械学習推論システムを構築したい... そのような方向けにサンプルとしてご参考頂ける内容をまとめています。(コンセプトの詳細は次項をご参照ください。)
EDGEPLANT T1 で手軽にエッジ推論を構築するメリット
(こちらはEDGEPLANT T1の宣伝も兼ねてるので、不要な方は読み飛ばしてください。)
弊社ではEDGEPLANTというハードウェアブランドを提供しており、その中でも機械学習の実行環境として利用できるハードウェアが EDGEPLANT T1 になります。
弊社が提供しているintdashと組み合わせることで、 EDGEPLANT T1で機械学習モデルを動かし、推論結果をintdashサーバーに時系列化された状態で送付することで、専用のWebアプリケーションでリアルタイムにデータを可視化したり、後から数種類のデータが時刻同期された状態でデータを確認することができます。
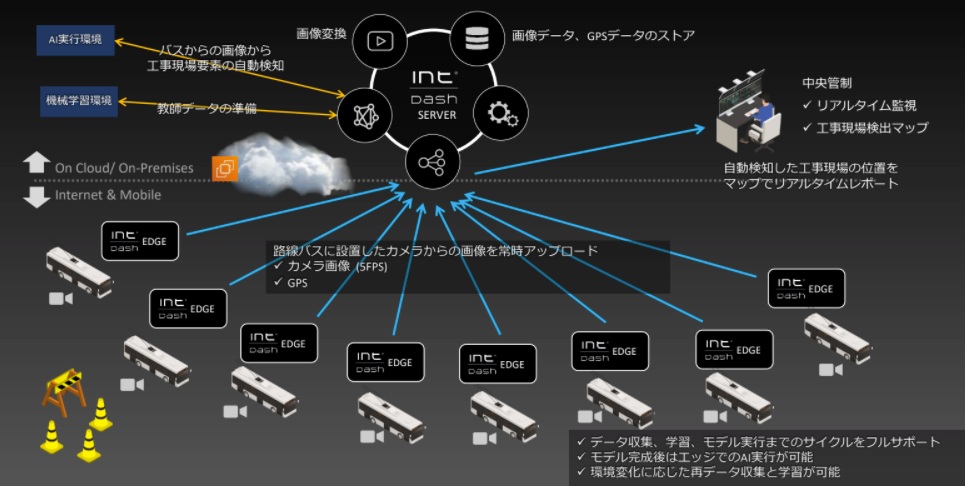
このしくみは、既にリリース発表されている大阪ガス様とのプロジェクトでも利用されています。
一方で、EDGEPLANT T1は単体でも購入することができます。しかしながらご購入いただいた方々からは「どうやってつかえばいいの?」、「システムとして組み込むにはどうすればよいの?」など、ざっくりシステムとして作りたいイメージはあるものの、具体的な実現手段がわからない…. こういう声を頂いておりました。
そこで今回は予算の都合などで「ユースケースを試して試験運用してみたいが、intdashとの連携まではなかなか手が出せない」方々向けに、皆様に馴染みの深いAWS様のサービスを存分に利用して、エッジ推論システムを手軽に構築するサンプルをご紹介いたします。
まずはEDGEPLANT T1で単純にモデルを動かしたい!という方は、こちらの記事をご参考ください。
今回のゴール
今回は、「ハードウェア側に機械学習環境を立てて推論を行い、クラウドに結果を収集して分析状況を確認する」システムを一人で構築したいと思います。
流れとしては
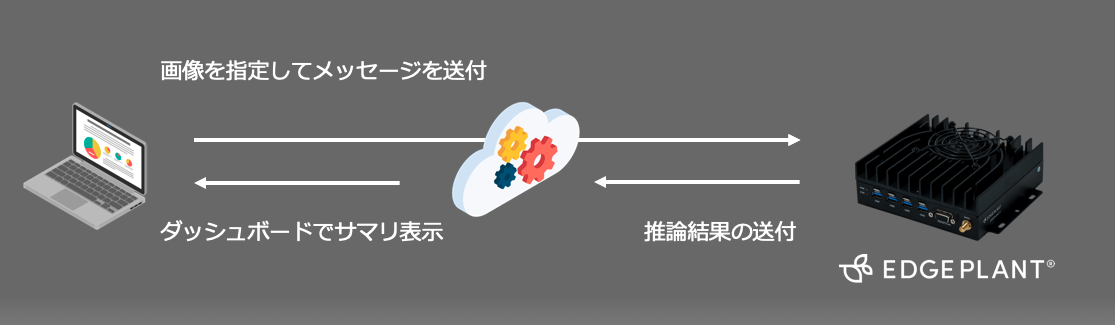
- 模擬クライアントから、画像を指定したメッセージを送る
- メッセージを待機しているEDGEPLANT T1がメッセージを受け取り、指定された画像に対して推論する
- 推論結果をサーバーに送る
- 1〜3を繰り返し、溜まったデータを分析ツールで可視化する
というイメージです。
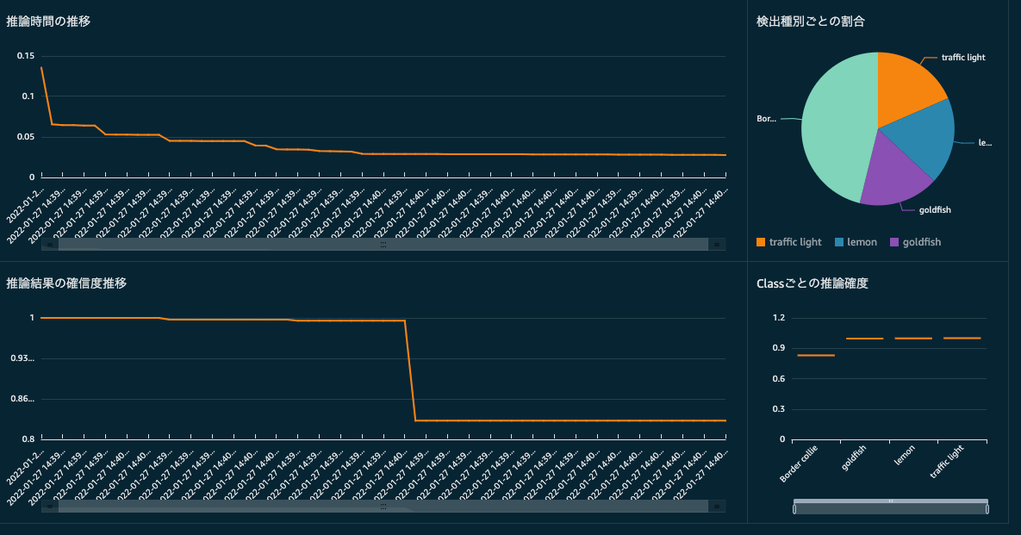
EDGEPLANT T1にはMXnetベースでトレーニングされたResNetというイメージ分類モデルをデプロイし、事前にEDGEPLANT T1に画像を数枚配置し、メッセージで指定された画像に対して何が写っているか推論してもらいます。ユーザーは遠隔で「推論結果の確信度」や「パフォーマンスの推移」を観察すると想定します。
最終的にはエッジ側の推論の様子を、以下のようなダッシュボードで確認できることを想定しています。
私が実施した際は各所でつまづき気が遠くなったときもありましたが、約3日程度で一通り構築できました。費用もデータ量に依存しますが、1000円かからないくらいの料金で試すことができました。
構成イメージ
AWS IoT Greengrassを利用したケースによくあるアーキテクチャに近いですが、以下のような構成を検討しました。
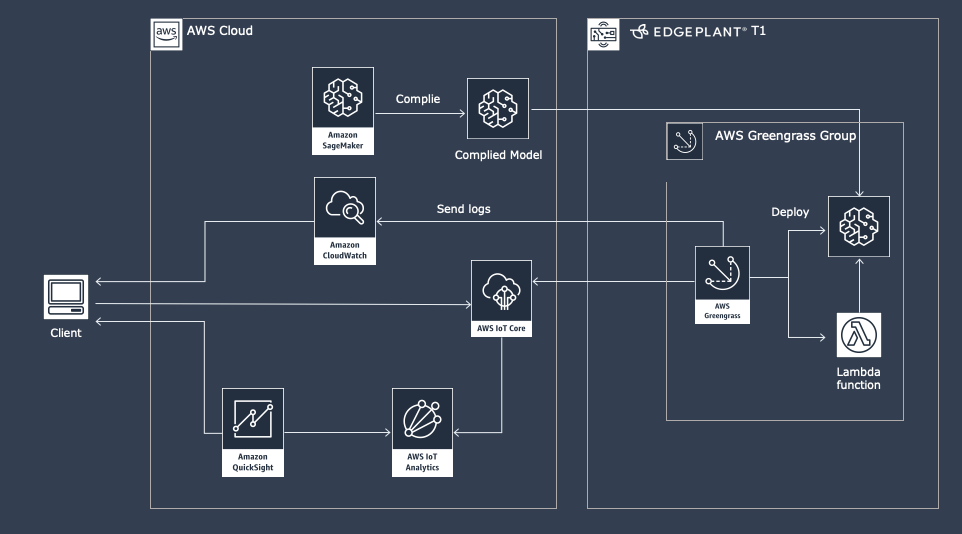
- モデルをEDGEPLANT T1で動作するように、Amazon SageMaker Neoを利用してコンパイルします
- EDGEPLANT T1で、モデルが動くように機械学習環境を構築します
- AWS IoT Greengrassを用いて以下のアセットをパッケージ化しデプロイします
- Lambda関数として作成された推論コード
- Amazon SageMaker Neoでコンパイルしたモデル
- デバイスとサーバー間のメッセージは、AWS IoT Coreを経由しMQTTメッセージでやりとりします
- EDGEPLANT T1からパブリッシュされたデータはAWS IoT Analyticsにて蓄積し、Amazon QuickSightでデータを可視化します
実際に構築してみる
それでは、実際に構築してみましょう。
モデルをAmazon SageMakerを用いてコンパイル
今回はMXnetのGluonCVから ResNetのモデルをダウンロードします。
from gluoncv import model_zoo import mxnet as mx model_name='ResNet50_v2' net = model_zoo.get_model(model_name, pretrained=True) net.hybridize() dummy = mx.nd.ones([1, 3, 224, 224]) _ = net(dummy) net.export(model_name, epoch=0)
ダウンロードしたモデルは、S3に格納しておきます。
import boto3 import tarfile session = boto3.session.Session() # compress packname = 'model.tar.gz' tar = tarfile.open(packname, 'w:gz') tar.add('{}-symbol.json'.format(model_name)) tar.add('{}-0000.params'.format(model_name)) tar.close() # send to s3 s3 = session.client('s3') bucket = 'sample-bucket' s3key = 'resnet-model/resnet-model' s3.upload_file(packname, bucket, s3key + '/' + packname)
次に、SageMaker Neoにてモデルを格納したS3のパスを指定してジョブを実行します。
# Replace with the role ARN you created for SageMaker sagemaker_role_arn = "arn:aws:iam::XXX:role/service-role/XXX" framework = 'mxnet' target_device = 'jetson_tx2' data_shape = '{"data":[1,3,224,224]}' # Specify the path where your model is stored s3_model_uri = 's3://{}/{}/{}'.format(bucket, s3key, packname) # Store compiled model in S3 within the 'compiled-models' directory compilation_output_dir = 'resnet-model/compiled-models/test' s3_output_location = 's3://{}/{}/'.format(bucket, compilation_output_dir) # Give your compilation job a name compilation_job_name = 'resnet-model5' sagemaker_client.create_compilation_job(CompilationJobName=compilation_job_name, RoleArn=sagemaker_role_arn, InputConfig={ 'S3Uri': s3_model_uri, 'DataInputConfig': data_shape, 'Framework' : framework.upper()}, OutputConfig={ 'S3OutputLocation': s3_output_location, 'TargetDevice': target_device}, StoppingCondition={'MaxRuntimeInSeconds': 900})
上記を実行するとコンパイルジョブが発生し、問題なければ完了します。コンソール上でもジョブのステータスを確認することができます。
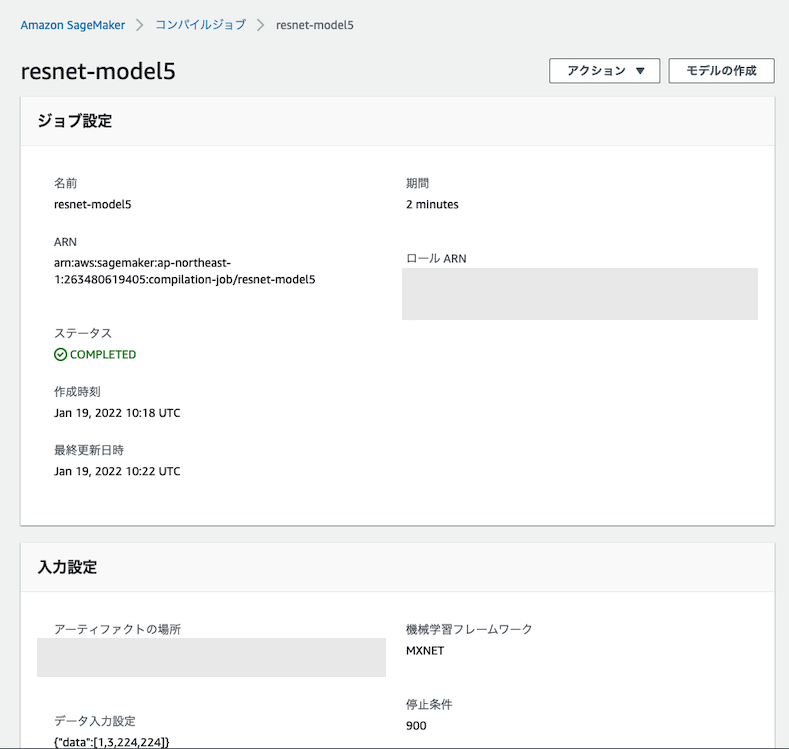
これで、コンパイルは完了しました。
EDGEPLANT T1で機械学習環境を構築する
T1でモデルが動くように、機械学習環境を構築していきましょう。このステップでは、AWSのドキュメントにもある通り Neo Deep Learning Runtime (DLR) をインストールします。
通常であれば pip install で DLRをインストールすれば完了しますが、EDGEPLANT T1ではJetson TX2を採用しており、JetPackのバージョンやOSのアーキテクチャと一致するDLRを用意する必要があります。そのため、T1上でDLRをビルドして用意します。
DLRの公式ページを参考に、ビルドします。
cmakeのビルド&インストール
sudo apt-get install libssl-dev wget https://github.com/Kitware/CMake/releases/download/v3.17.2/cmake-3.17.2.tar.gz tar xvf cmake-3.17.2.tar.gz cd cmake-3.17.2 ./bootstrap make -j4 sudo make install
DLRのビルド&インストール
git clone --recursive https://github.com/neo-ai/neo-ai-dlr cd neo-ai-dlr mkdir build cd build cmake .. -DUSE_CUDA=ON -DUSE_CUDNN=ON -DUSE_TENSORRT=ON make -j4 cd ../python python3 setup.py install --user
インストールし終えたら、実際にpython上でimport できるか試してみます。
root@aptuser-desktop:/greengrass/ggc# python
Python 3.8.6 (default, Jan 24 2022, 21:19:25)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dlr
CALL HOME FEATURE ENABLED
You acknowledge and agree that DLR collects the following metrics to help improve its performance.
By default, Amazon will collect and store the following information from your device:
(省略)
>>>
DLRの初期ロード時の注意書きが出力され、無事importができました。
⚠️ 注意 私が確認したときはAWS Lambdaの制約によりアーキテクチャがarm64の場合、 Python3.8 以上でないと対応しておりませんでした。バージョン3.8未満を利用されている方は Pythonのバージョンをアップデートすることをおすすめします。
EDGEPLANT T1にAWS IoT Greengrassをインストールする
AWS IoT Greengrassに関連した手順は、基本的に以下手順に沿って実施しています。
まず最初にEDGEPLANT T1に AWS IoT Greengrassをインストールします。初期手順についてはこちらの手順のModule1〜Module2を参考にしました。
Module1は、Greengrassがアクセスする用のユーザーを設定するパートです。私は以下手順を実施しました。
sudo adduser --system ggc_user sudo addgroup --system ggc_group
上記のドキュメントではopenjdk-8-jdk をインストールする手順がありますが、今回はGreengrass Managerは利用しないのでスキップしました。
Module2はAWS IoT Greengrassの画面上でデバイス情報を新規作成し、作成されたクライアント認証情報をダウンロードしてセットアップします。
最終的にEDGEPLANT T1上で以下の動作が確認できたら完了です。
root@aptuser-desktop:/greengrass/ggc# core/greengrassd start Setting up greengrass daemon Validating hardlink/softlink protection Waiting for up to 1m10s for Daemon to start Greengrass successfully started with PID: 28776
推論を行うコードをLambdaとしてデプロイする
実際にモデルの推論を行うソースコードをAWS Lambdaにデプロイします。
まず、AWS IoT Greengrass経由でSubscribeしたメッセージをトリガーに、モデルを動作させて推論した結果をPublishするコードをAWS Lambda上にデプロイします。
サンプルとして、以下のコードを用意しました。こちらも公式サンプルをほぼ参照しております。 (一部前処理など公開の都合上省略しています)
import logging import os from dlr import DLRModel from PIL import Image import greengrasssdk import numpy as np import json import time # Initialize logger customer_logger = logging.getLogger(__name__) # Create MQTT client mqtt_client = greengrasssdk.client('iot-data') # Initialize model_resource_path = os.environ.get('MODEL_PATH', '/ml-model') print(model_resource_path) dlr_model = DLRModel(model_resource_path, 'gpu', 0) # Load Synset synset_path = os.path.join('', '/home/aptuser/develop/t1-ml-workflow/synset.txt') with open(synset_path, 'r') as f: synset = eval(f.read()) def softmax(x): e_x = np.exp(x) sum_x = np.sum(e_x) return e_x/sum_x def predict(image_path): """ Predict image with DLR. The result will be published to MQTT topic '/resnet/predictions'. :param image: numpy array of the Image inference with. """ print('start prediction process.......') im = Image.open(f'/home/aptuser/develop/t1-ml-workflow/{image_path}') im = np.asarray(im.resize((224,224))) im = im.astype(np.float32) if len(im.shape) == 2: # for greyscale image im = np.expand_dims(im, axis=2) input_data = {'data': im} print('start prediction.') load_start_time = time.time() out = dlr_model.run(input_data) finished_time = time.time() print('finished.') top1 = np.argmax(out[0]) prob = np.max(softmax(out[0])) prediction_time = finished_time - load_start_time exe_time = str(datetime.datetime.now()) result = { 'class': synset[top1], 'probability': float(prob), 'prediction_time': finished_time - load_start_time, 'time': exe_time } # Send result send_mqtt_message(result) def send_mqtt_message(message): """ Publish message to the MQTT topic: '/resnet-50/predictions'. :param message: message to publish """ mqtt_client.publish(topic='/resnet/predictions', payload=json.dumps(message)) # The lambda to be invoked in Greengrass def lambda_handler(event, context): print(f'subscribed message: {event}') try: predict(event['message']) except Exception as e: customer_logger.exception(e) send_mqtt_message( 'Exception occurred during prediction. Please check logs for troubleshooting: /greengrass/ggc/var/log.')
Lambda関数を作成し、上記のコードをデプロイします。
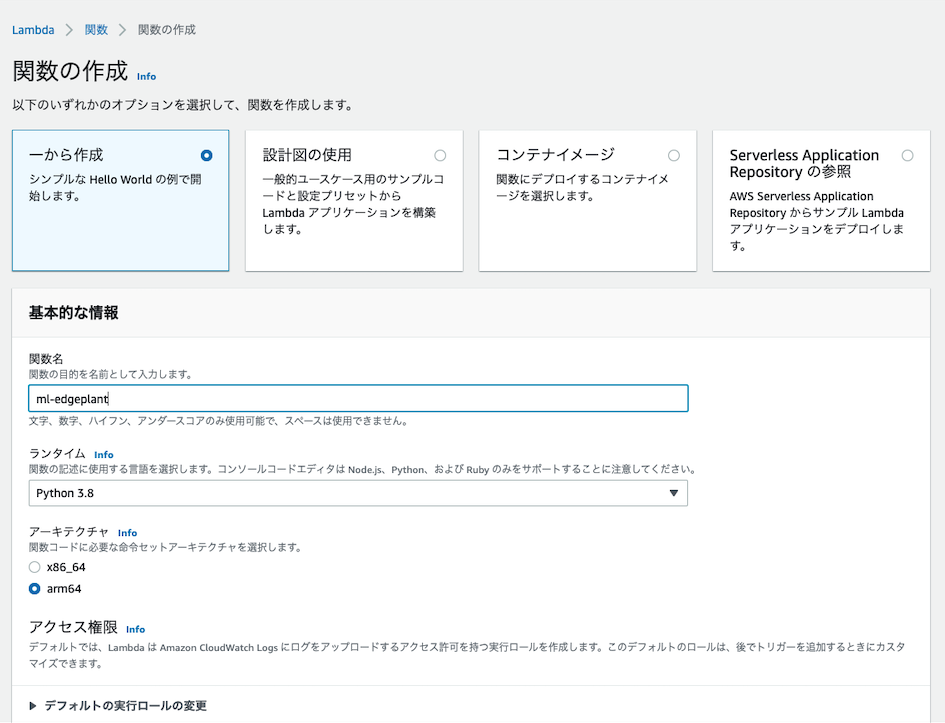
このとき、JetsonTX2の場合は arm64をアーキテクチャとして指定する必要がありますが、残念なことにPython 3.7以下のバージョンは利用できませんでした。そのためPython3.8以上を利用します。
バージョンを発行し、エイリアスに紐付けて作成します。
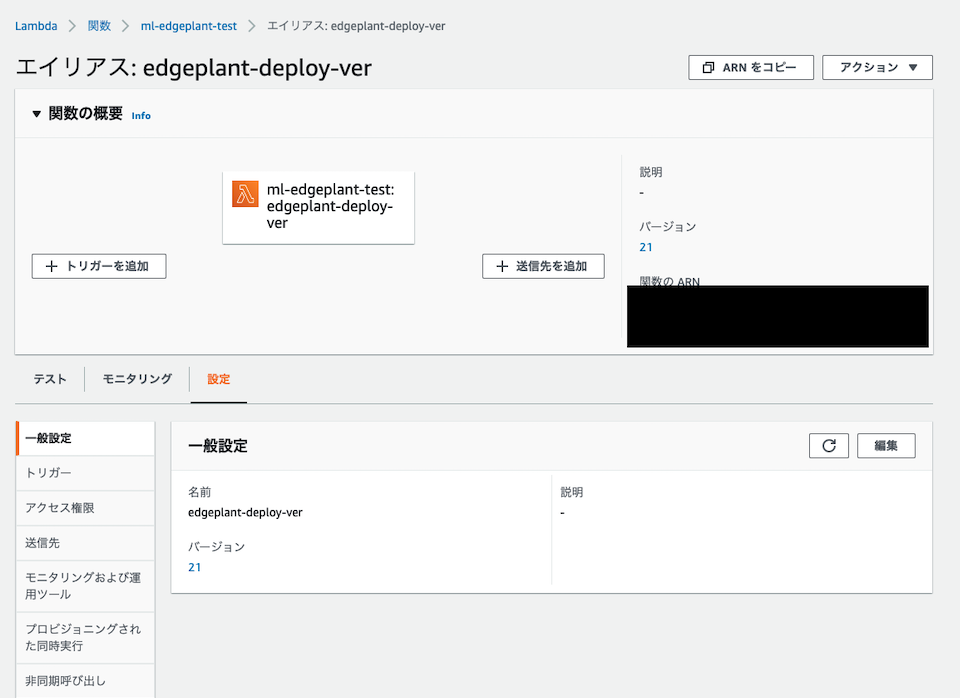
これで、Lambda関数の準備も完了です。
LambdaをGreengrass Groupに追加する
先程作成したLambda関数をGreengrassのグループに追加します。
詳細の手順は Step 4: Add the Lambda function to the Greengrass group を参考にしてください。
SageMakerでコンパイルしたモデルをGreengrass Groupに追加する
先程作成したSageMaker Neoでコンパイルしたモデルをグループに追加します。
詳細の手順は Step 5: Add a SageMaker Neo-optimized model resource to the Greengrass group を参考にしてください。
推論実行用のローカルデバイスをGreengrass Groupに追加する
今回のGreengrassの設定で、Lambda関数をコンテナ形式で動作させる設定にしたため、GPUにアクセスできるように設定する必要があります。章の冒頭で触れているこちらのドキュメントの末尾にある”Configuring an NVIDIA Jetson TX2”に、設定すべきデバイスとボリュームのパスが書かれています。
基本的な手順は、こちらの手順と同じです。
Greengrassの"グループ"から"リソース" を選択し、"ローカルリソースの追加"を押下します。リソースの作成画面が開くので、各デバイスのパスを入力します。
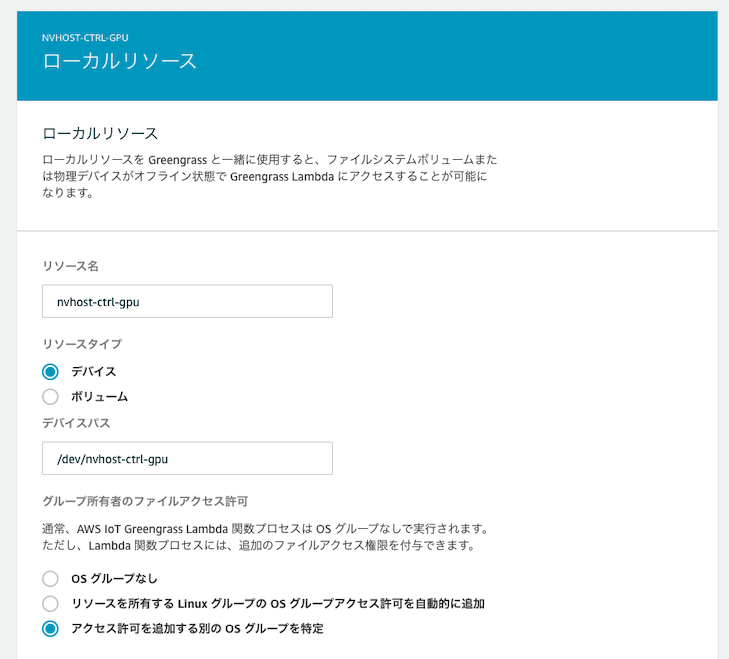
”Configuring an NVIDIA Jetson TX2”に記載されているDevice Pathを指定してください。
| name | path |
|---|---|
| nvhost-ctrl-gpu | /dev/nvhost-ctrl-gpu |
| nvhost-dbg-gpu | /dev/nvhost-dbg-gpu |
| nvhost-ctrl | /dev/nvhost-ctrl |
| nvmap | /dev/nvmap |
| nvhost-prof-gpu | /dev/nvhost-prof-gpu |
ちなみに、上記を追加せずGreengrassを起動すると、Lambda関数側で以下のエラーが表示されます。
[2022-01-25T00:13:01.06+09:00][ERROR]---------------------------------------------------------------- [2022-01-25T00:13:01.06+09:00][ERROR]-An error occurred during the execution of TVM. [2022-01-25T00:13:01.06+09:00][ERROR]-For more information, please see: https://tvm.apache.org/docs/errors.html [2022-01-25T00:13:01.06+09:00][ERROR]---------------------------------------------------------------- [2022-01-25T00:13:01.06+09:00][ERROR]- Check failed: (e == cudaSuccess || e == cudaErrorCudartUnloading) is false: CUDA: no CUDA-capable device is detected
同様に、ボリュームも”Configuring an NVIDIA Jetson TX2”に記載されているパスを指定します。 他にもLambda関数側でアクセスしているボリュームがあれば、同じように指定します。
| name | path |
|---|---|
| shm | /dev/shm |
| tmp | /tmp |
※ 今回はサンプルなのでセキュリティを考慮していませんが、 実際に利用する場合はGreengrassのアクセス許可がセキュリティ的に問題ないか、 しっかり検討した上で指定のリソースを参照してください。
サブスクリプションを定義する
先程のパート「推論を行うコードをLambda関数としてデプロイする」にて、プッシュされたメッセージを参照に推論を実施し、AWS IoTにPublishするコードを書いていたと思います。ここでは、そのAWS IoTとLambda関数のサブスクリプションを定義します。
今回も、こちらの手順を実行しました。
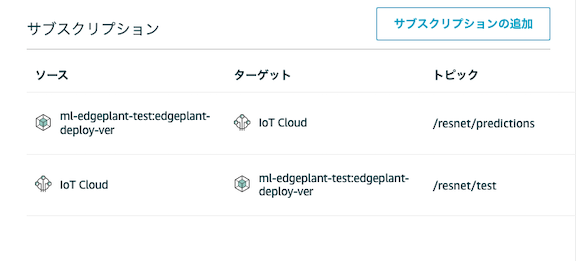
| トピック | 説明 |
|---|---|
| /resnet/predictions | IoT Cloud上のMQTTクライントからプッシュされるメッセージをLambda関数でサブスクライブするトピック |
| /resnet/test | Lambda関数からプッシュされるメッセージをサブスクライブするトピック |
これで、デプロイパッケージができました!!
それでは、早速デプロイしてみましょう。デプロイの手順はこちらを実施します。
上記手順後、デバイス側での動作状況をCloudWatchで確認します。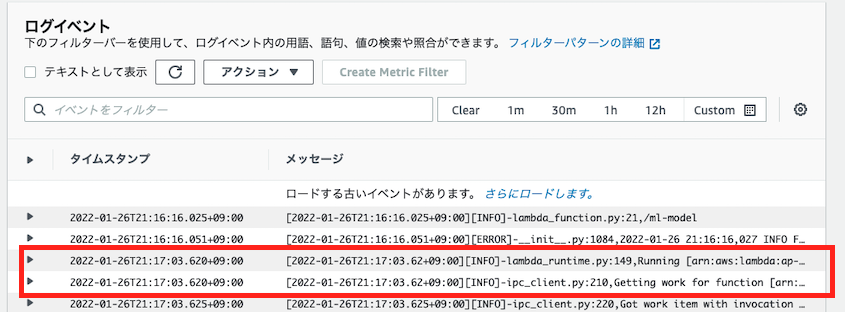
[2022-01-25T15:31:21.811+09:00][INFO]-lambda_runtime.py:149,Running [arn:aws:lambda:ap-northeast-1:XXXXXXXXX:function:ml-edgeplant-test:6] [2022-01-25T15:31:21.811+09:00][INFO]-ipc_client.py:210,Getting work for function [arn:aws:lambda:ap-northeast-1:XXXXXXXXX:function:ml-edgeplant-test:6] from http://localhost:8000/2016-11-01/functions/arn:aws:lambda:ap-northeast-1:XXXXXXXXX:function:ml-edgeplant-test:6/work
上記のログが出力され待機状態になっていればOKです!
デプロイパッケージをテストする
パッケージのデプロイが完了したので、実際に各サブスクリプションが正常に定義されているか試してみます。
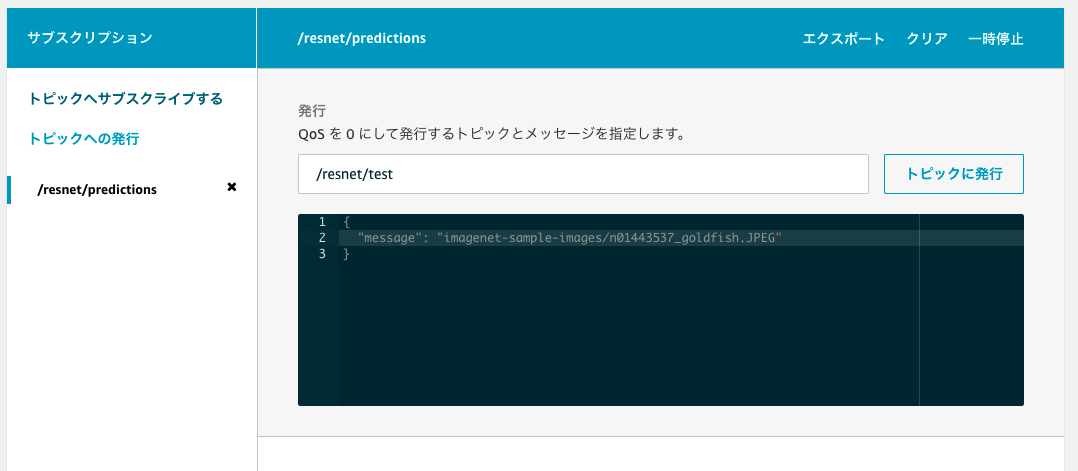
こちらの手順と同様に、AWS IoTのテストクライアントでメッセージを送ってみましょう。
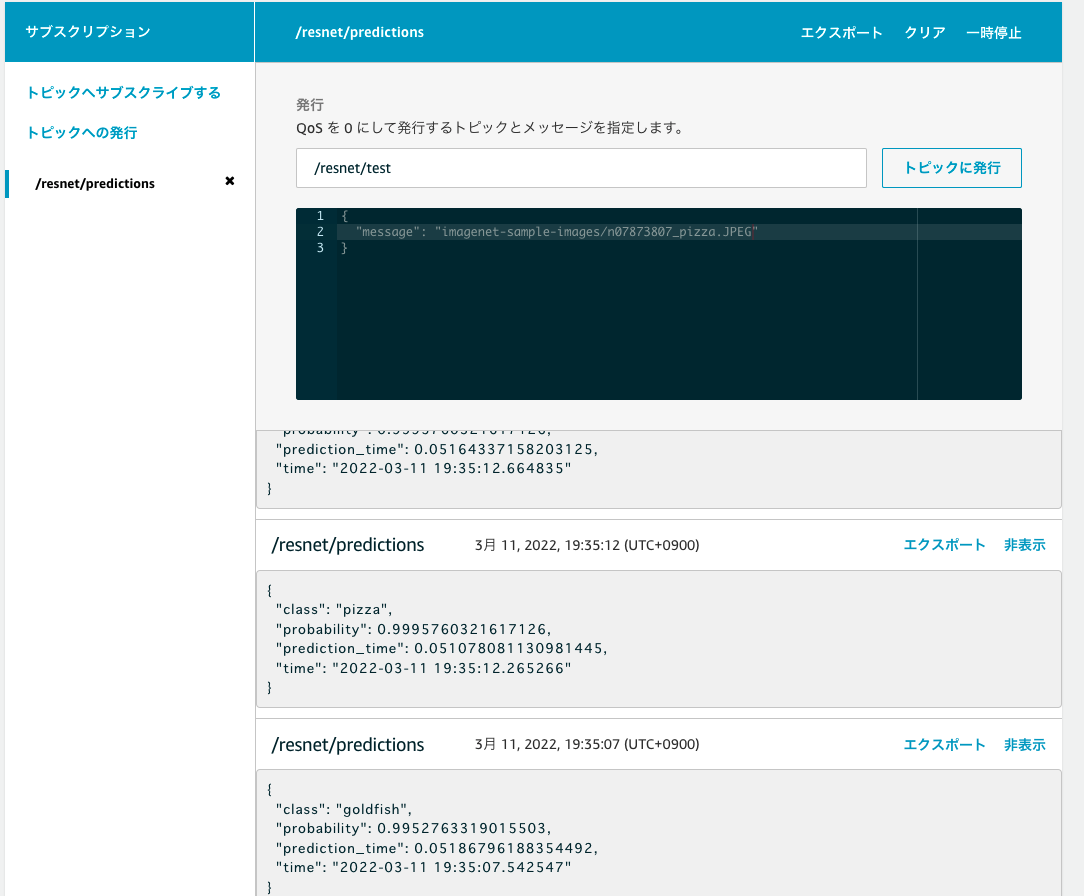
今回は、テストクライアント側でサブスクライブするトピックを /resnet/predictions に指定します。

指定後、トピックに紐付いたサブスクライブの項目が出てくるので、そちらでトピックを /resnet/test と指定し発行します。今回は goldfish の画像を指定します。
すると、モデルの出力結果が返ってきました! goldfish と期待通りの推論結果が返ってきていることが確認できます。
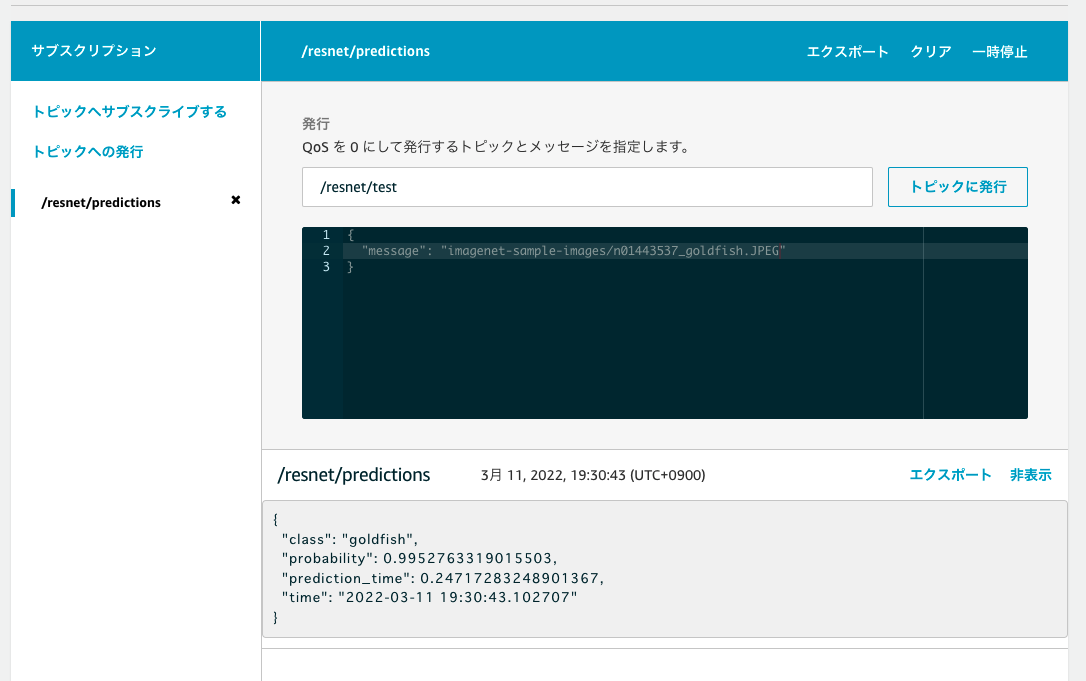
EDGEPLANT T1側の設定はこれで完了です。
IoT Analytics にデータセットをためる
ようやくEDGEPLANT T1からAWS IoTにデータを送れるところまでできたので、次はそのデータをIoT Analyticsに投下しデータセットとして溜めていきます。
こちらの手順に従い設定を行います。
チャネルの作成
チャネルの作成では、先程指定した /resnet/predictions を指定します。
データセットの作成
データセットの作成では、定期的にデータセットに溜めたいデータを出力できるクエリを定義します。今回はすべての項目をそのまま参照したいので、すべてのデータをクエリするようにしました。
SELECT * FROM edgeplant_project_datastore
スケジュールは、1分間に一回実行するようにします。
パイプラインの作成
パイプラインでは、Lambda関数が送付しているJSONの各項目とデータ型を指定します。
上記の手順が終了したらテストしてみましょう。 先程のパート「デプロイパッケージをテストする」で実施した手順を複数回実施して、AWS IoT側が受け取ったメッセージがデータストアに蓄積されているか確認します。
メッセージごとに、指定の画像を切り替えながら複数回トピックを発行します。
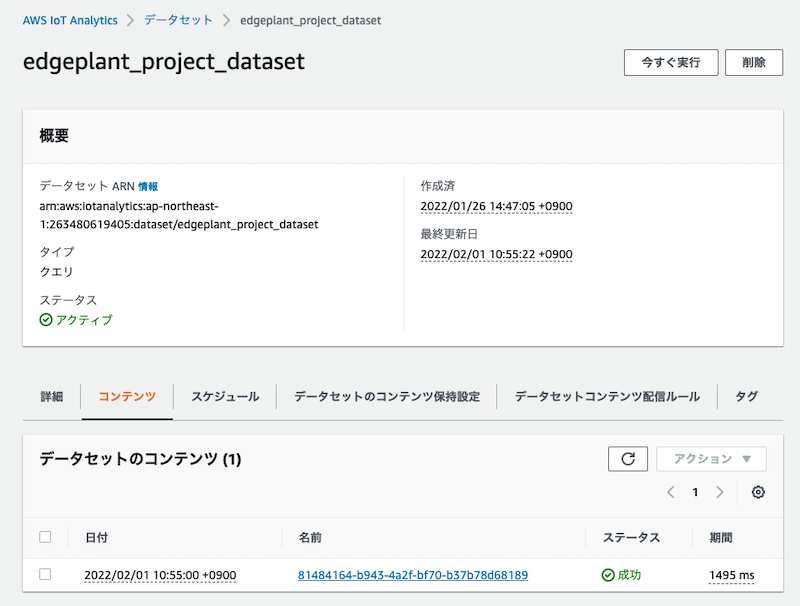
AWS IoT Analyticsに戻り、データセット > コンテンツ をクリックすると、コンテンツが生成されていることが確認できます。
このコンテンツをクリックし、実際にデータが格納されている様子を確認します。
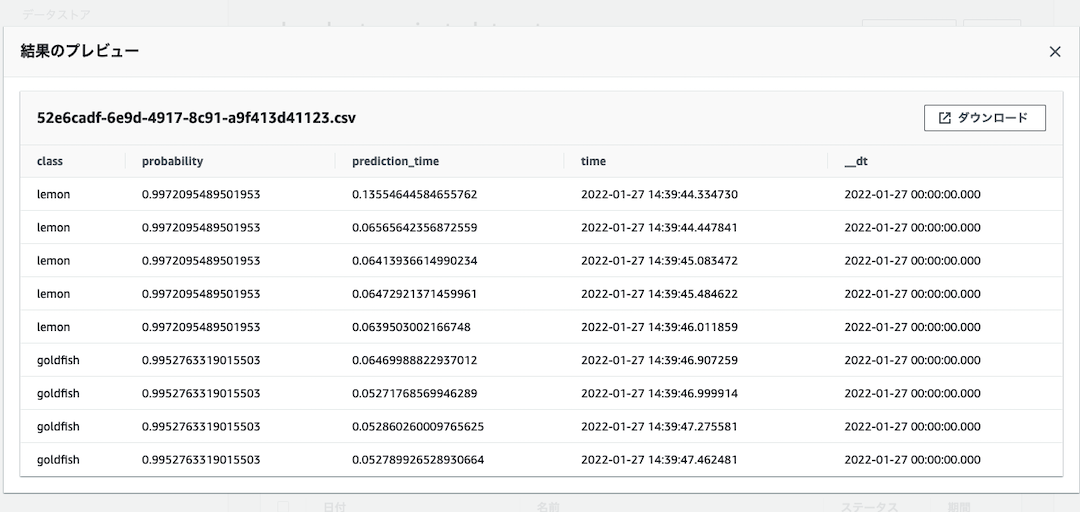
無事、データが蓄積している様子を確認することができました。
QuickSightでダッシュボードを作り結果を確認する
いよいよ最後のパートになります。QuickSightを使って、ダッシュボードを作ります。
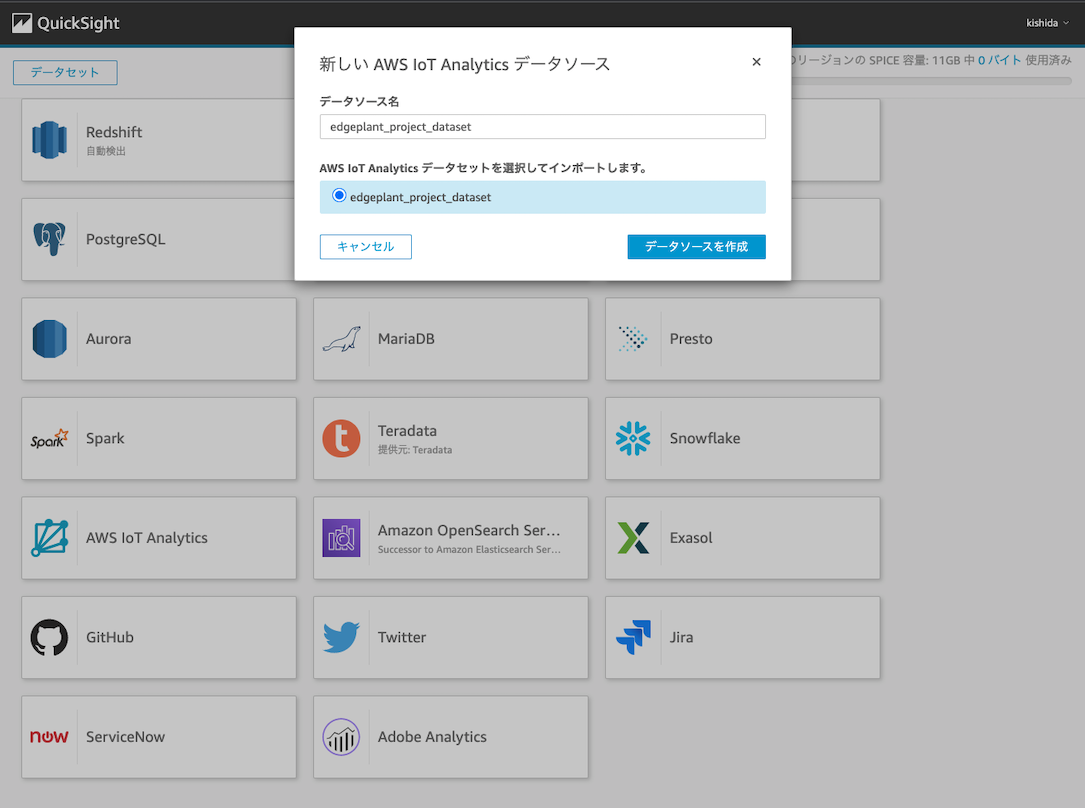
まずデータセットを作成します。"データセット"の項目をクリックし、"新しいデータセット"をクリックします。すると、参照先のサービスの一覧がでてきます。今回は AWS IoT Analyticsを参照します。
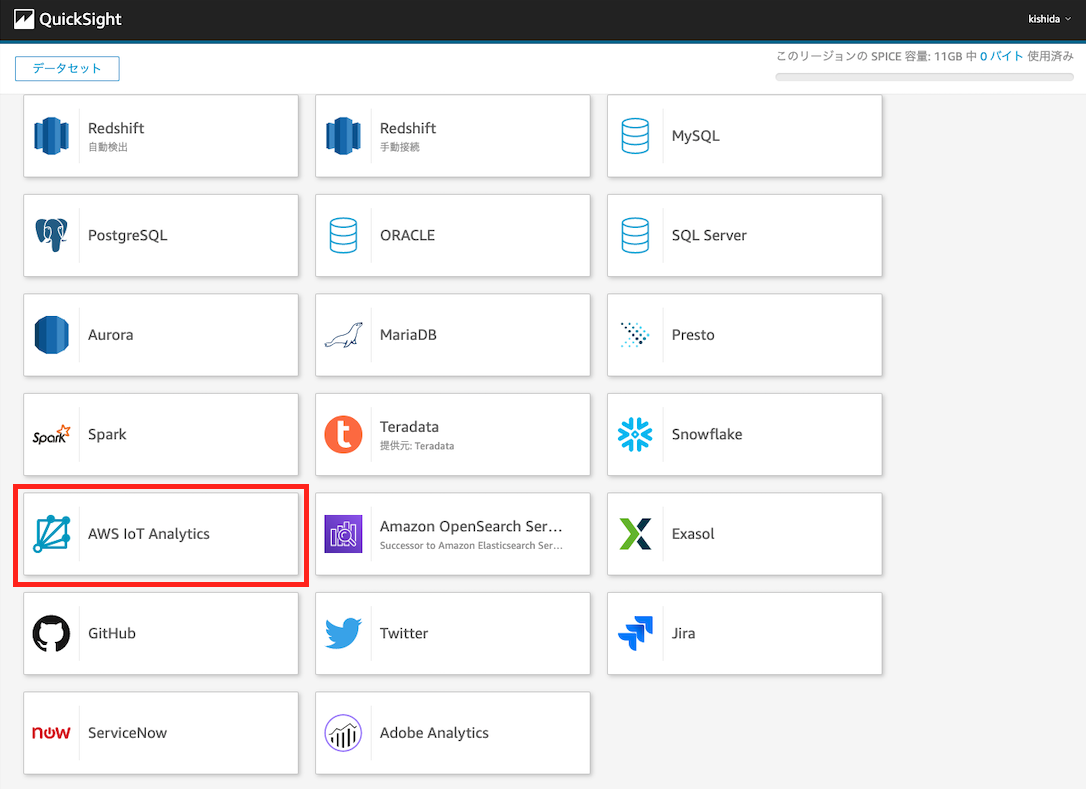
すると、既に作成したデータセットが表示されるので、指定のデータセットを選択して “データソースを作成“をクリックします
“分析“で “新しい分析“をクリックし、対象のデータセットを参照します
自分が可視化したいデータに合わせて、パーツを選びダッシュボードを構築します。

最終的には、以下のようなダッシュボードが作成できます。自分が評価したい数値をベースに、オリジナルのダッシュボードを構築してみましょう。
ダッシュボードが完成したら、全作業が完了です。 お疲れ様でした!
まとめ
今回は、EDGEPLANT T1とAWSのサービスを活用することで、手軽にエッジ推論システムが構築できました。このサンプルを利用することで、以下のようなケースに応用することができると思います。
- 自分の希望するモデルに差し替えて、すぐにシステムにデプロイできる
- 台数を増やしたいときは、AWS IoT Greengrassでデプロイするだけでシステムに組み込める
EDGEPLANT T1をシステムとして活用したいとなった場合、EDGEPLANT T1でモデルを動かすだけではなく、その推論結果をクラウドに蓄積し、分析や再学習に応用したいケースに発展することが多いです。しかしながら、そのシステムを構築するのにも費用や時間がかかってしまう… そのようなときに、今回のサンプルを利用することができます。
ちなみに以下のような要望がある場合は今回のシステムでは実現が難しいので、ぜひ弊社のintdashの活用をご検討ください。
リアルタイムで推論状況を確認したい
AWS IoT AnalyticsおよびAWS Quick Sightは、基本的にバッチ処理でデータを処理するため、リアルタイムで推論状況を確認することができません。intdashでは、高粒度データのリアルタイム送受信を可能にし、再生に特化した高機能ダッシュボードをご活用いただけます。
他のセンサーデータを同期させながらデータを収集・管理したい
機械学習モデル以外に、走行中の動画データや、CANなどの他データと同期しながらデータを収集・管理したい場合、このしくみでは達成できません。intdashでは、複数に横断した高粒度データを、ミリ秒単位で同期させデータを収集し、あとから管理することができます。
intdashを検討する前の手軽な機械学習システムを構築する、という位置づけで、ぜひご参考いただけると嬉しいです。
それでは、最後までお付き合いいただきありがとうございました!