みなさま、こんにちは。研究開発グループと製品開発グループ に兼務で所属しております、きしだです。aptpod Advent Calendar 2020 11日目を担当します。今回は機械学習に関わるエンジニア向けに、最近AWSがリリースしたAWS Lambdaの新機能を利用して、サクッと推論APIを作るネタをご紹介します。
推論をすばやくAPI化する意義
その前に、推論箇所をAPIとしてすばやく用意できる必要性について簡単に触れたいと思います。
機械学習関係の案件では、お客様側も理解できるKPIを立てることが非常に重要視されています。例えば「モデルの正解率を〜にしたい」や「モデルの動く速さを〜にしたい」などですね。これらの具体的な数値はお客様と議論を重ね、お互いにしっくりくる数値に落とし込む必要があるのですが、これがとてもむずかしいのです。なぜでしょうか。
- お客様と開発側で共に運用イメージがわかず、モデルに対して運用時の影響力がピンとこない
- 具体的な運用イメージをすべて仮説ベースで作り上げるため、仮説にほころびが生まれやすく議論が錯綜する
上記に心当たりがある方もいらっしゃるのではないのでしょうか。これらはいずれも「システム運用を前提としたモデルの使い方をお客様側でイメージできていない」ことに起因します。このときにAPIまでを用意してお客様に共有すると、以下のようなことが期待できます。
- APIを叩くだけで推論結果が返ってくるので、お客様側もモデルを試しやすい
- APIとして用意されているので一時的にシステムに組み込むことができ、試験運用が可能になる
- 必要最低限の費用で、お客様側で運用しながらモデルをさわることができる
- ガチガチにシステムを作るより、まずは小さく簡単なシステムから始めることでイテレーションを回せる
いいこと尽くめですね。お客様側もモデルにふれる機会がグッと増え、議論を活発にまわすことができ、より納得感をもってすすめることができます。そのためにモデル開発に留めず運用側に一歩踏みこむ姿勢が大事になり、モデルの推論箇所をAPIとしてすばやく用意することが必要になります。
今回の記事はその一歩のヒントになるよう、私が検証した内容の一部をご紹介するものです。
AWS Lambda コンテナサポートの嬉しいポイント
AWS Lambdaといえば、 「サーバーのことを意識しないサーバーレスコンピューティングを提供してくれるサービス」で、アプリケーションをすばやく実行環境に持っていきたい時に重宝する素晴らしいサービスです。それだけでなく、Amazon API Gateway などの他サービスをトリガーにしたイベント定義も楽々できることで有名ですよね。
機械学習の実行環境もAWS Lambda上で動かせたら楽だろうなぁと思う時がありつつも、以下の制約により断念していました。
- パッケージの割り当て量が 250MB
- Lambda向けにパッケージを作る際、依存パッケージが多いと手間がかかる
- ローカルテスト/デバッグはAWS Lambdaだけでお手軽にできない
とくに容量制限が厳しく、機械学習の場合はTensorFlowやらKerasなどの大きめのパッケージを使用することが多いため、到底250MBに抑えるなんてことはできません。
しかしながら冒頭に記載のAWSのリリース内容では、 大きく以下のような内容がピックアップされていました。
- コンテナイメージをそのままLambda関数としてデプロイできる
- コンテナイメージは10GBまでならデプロイ可能
- ローカルで実行できるLambdaのRuntime APIツール Lambda Runtime Interface Emulator がオープンソース化される
パッケージの容量が大きく緩和され、コンテナイメージ向けのローカルテストツールも提供されるとのことです。これは、従来のLambdaに対して抱いていた課題感をすべて払拭してくれる予感がしますね。
前置きが長くなってしまいましたが、試してみないわけにはいかない! ということで、実際に動かして見ましょう。
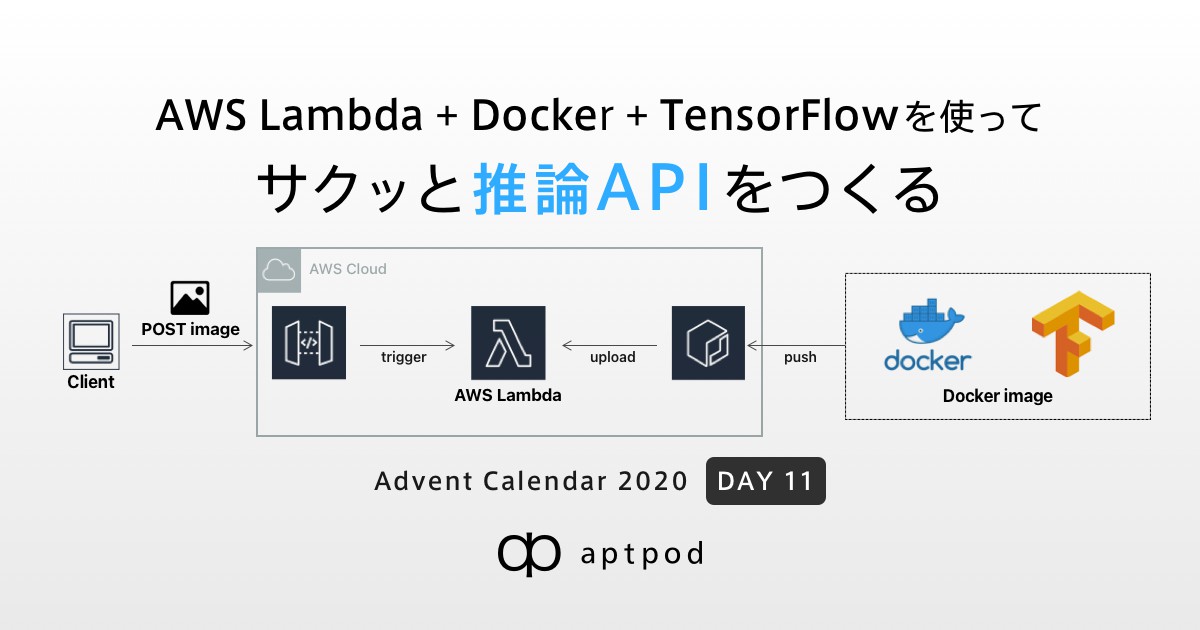
構成
今回は、こちらのTensorFlowを使用した「車両を検出するモデル」を、AWS Lambda上で動かしてみます。 *1
以下のように、Amazon API Gatewayと連携させてクライアントPCから画像をPOSTすると、車両の検出結果を返すAPIを作ります。

- TensorFlowで作成されたモデルが動くコンテナイメージを用意しAmazon ECRにPushします
- AWS Lambda上でLambda関数を作成、Amazon API Gatewayと紐付けて画像のPOST用APIを用意します
コンテナイメージを作ってローカルでテストする
まずはコンテナイメージを作ってみましょう。
手元にあるコンテナをそのまま使えばよいのではなく、AWS Lambda向けにコンテナを作りなおす必要があります。
理由としては、Lambda Runtime API を実装する Lambda Runtime Interface Clients を取り込む必要があるためです。このクライアントを実行するためにいくつか依存ライブラリをインストールしなければいけません。
上記をふまえ、以下のようなDockerfileを準備します。
# Define function directory
ARG FUNCTION_DIR="/function"
FROM tensorflow/tensorflow:1.14.0-py3
# Install aws-lambda-cpp build dependencies
RUN apt-get update && \
apt-get install -y \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev \
libsm6 \
libxrender1 \
libxtst6 \
# Install for vehicle detection
python3-dev \
libsm6 \
libxext6 \
libxrender-dev \
libgl1-mesa-dev \
python3-tk
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Create function directory
RUN mkdir -p ${FUNCTION_DIR}
# Copy function code
COPY app/app.py ${FUNCTION_DIR}/app.py
COPY app/lib/ ${FUNCTION_DIR}/lib/ # other python file
RUN mv ${FUNCTION_DIR}/lib/* ${FUNCTION_DIR}
# Install the runtime interface client & other python package
COPY requirements.txt /
RUN pip install --upgrade pip && \
pip install awslambdaric && \
pip install --target ${FUNCTION_DIR} --no-cache-dir -r requirements.txt
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# (optional) for TEST
COPY aws-lambda-rie /usr/bin/
RUN chmod 755 /usr/bin/aws-lambda-rie
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
CMD [ "app.handler" ]
いくつかポイントを記載します。
# (optional) for TEST COPY aws-lambda-rie /usr/bin/ RUN chmod 755 /usr/bin/aws-lambda-rie
コンテナをローカルでテストする際は、冒頭で紹介の通り Runtime interface emulator を使います。ローカルでテストしたい場合はAWSの公式ドキュメントに従い、インストールしておきましょう。 (※コンテナにいれなくても、コンテナ実行時にマウントする方法もあるのでここは任意です)
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ] CMD [ "app.handler" ]
実行時は、 Lambda Runtime Interface Client により対象の関数が呼び出されます。上記を実行するため ENTRYPOINT でクライアントの実行コマンド、 CMD で対象関数を指定します。 (今回は app.pyのhandler 関数を対象)
上記の準備ができたら、buildします。
docker build -t serverless-function:latest .
buildできたら、まずはローカルで動作するか確認します。
以下を実行します。
docker run -p 9000:8080 --entrypoint /usr/bin/aws-lambda-rie --name serverless --rm serverless-function:latest /usr/local/bin/python -m awslambdaric app.handler
すると、以下のようにコンテナ内のLambda Runtime APIが動作します。
time="2020-12-08T07:30:14.459" level=info msg="exec '/usr/local/bin/python' (cwd=/function, handler=app.handler)"
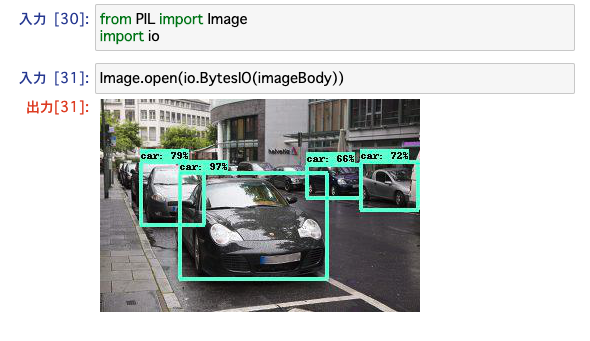
早速エミュレーターが提供しているエンドポイントを叩いて見ましょう。 以下の画像をエンドポイントに投げてみます。

以下はクライアント側をPythonで簡単に書いたものです。
# Amazon API Gatewayの代わりに base64にencode data = base64.b64encode(f.read()) data = {"body":data} response = requests.post("http://localhost:9000/2015-03-31/functions/function/invocations", json=data) contents = json.loads(response.content) imageBody = base64.b64decode(contents["body"]) Image.open(io.BytesIO(imageBody))
上記を実行すると、コンテナ側のログが出力されていました。
START RequestId: 11be1529-4ae3-47f4-8aee-2e81fe7a63e5 Version: $LATEST /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. ・・・ 2020-12-08 07:30:45.707671: W tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile. END RequestId: 11be1529-4ae3-47f4-8aee-2e81fe7a63e5 REPORT RequestId: 11be1529-4ae3-47f4-8aee-2e81fe7a63e5 Init Duration: 2.54 ms Duration: 7020.34 ms Billed Duration: 7100 ms Memory Size: 3008 MB Max Memory Used: 3008 MB
Jupyter notebook側でもデータが返ってきました。
推論もできている様子です👍
ECRにプッシュし、AWS Lambda上で実行してみる
いよいよ実環境へのデプロイです。 ECRに先ほど作成したコンテナイメージをpushします。(docker loginが必要ですのでご注意ください)
docker tag serverless-function:latest {AWS_ACCOUNT_NO}.dkr.ecr.ap-northeast-1.amazonaws.com/vehicle-detection-api:latest
docker push {AWS_ACCOUNT_NO}.dkr.ecr.ap-northeast-1.amazonaws.com/vehicle-detection-api:latest
コンソールを見ると無事pushできていました。

次に Lambda関数を作成してみます。関数の作成時、「コンテナイメージ」を選択するとECRにコミットされているコンテナイメージを選択することができます。

これで無事作成できました。
次にAmazon API Gateway を連携させて、推論したい画像データをPOSTするためのAPIを構築します。

無事構築できたので、ローカルの時と同様に画像を送付してみます。
ローカルテストと同様に、クライアント側として以下のコードを用意します。
response = requests.post(
"https://{API_GATEWAY_CODE}.execute-api.ap-northeast-1.amazonaws.com/default/vehicle-endpoint-test",
data=data,
headers=header
)
imageBody = base64.b64decode(response.content)
Image.open(io.BytesIO(imageBody))
上記を実行すると....以下のように車が推論された結果が返ってくることが確認できました!

予想より簡単に推論エンドポイントを立てることができました! 🎉
使ってみた感想
一通り試してみた感想をまとめておきます。
良かった点
- 予め用意したコンテナをベースにLambda向けにビルドし直せばいいので、環境の作り方が楽!
- AWS Lambda Runtime API との連携テストもローカルで実施しやすくなり、環境準備がしやすい!
今後の課題となりそうな点
- 基本Lambda関数の実行時の仕様は変わらず。AWS Lambdaの仕様でデータのキャッシュはできないので、推論する場合毎度モデルをロードする必要がある
- ローカルでテストできるのは Lambda Runtime API経由のみなので、Amazon API Gatewayなどの他サービスとの連携までを見据えたテストまで完結することはむずかしい
まとめ
AWS Lambda上に推論環境として構築したコンテナイメージをデプロイし、Lambda関数として動かすことができました。外部に共有できるAPIとしてはまだ課題はありそうですが、とても簡単に試すことができるのでケースに当てはまりそうな方がいたらぜひ活用してみてください!
ちなみに余談ですが、弊社製品のintdashというデータストリーミングプラットフォームと今回の推論APIのような機械学習ツールと連携すると、データの収集から推論まで行えるシステムをサクッと作れます。 もしまた機会があれば、今年リリース発表された intdash SDK for Python を使って、今回構築したAPIとintdashを連携したパターンもやってみたいと思います。
intdash SDK for Python のリリース発表はこちら
ご覧いただきありがとうございました!