
はじめに
こんにちは、SREチームの金澤です。
弊社はintdashというIoTプラットフォームを展開しています。そのサーバサイドであるintdash Serverはクラウドインフラを用いた構築が多く、その一つがAmazon Web Service(AWS)です。
パブリッククラウドを使用する上で気をつけたい点の一つとして障害の把握が挙げられます。サービス障害の要因確認として役立ち、その内容をもとに今後のプロアクティブな対策を検討する助けにもなります。また大規模の障害の場合はお客様が把握されている可能性も高く、いただいたご質問にスムーズな回答を差し上げる一助にもなります。素早く把握していることに越したことはありません。
そのような体制を目指すべくまずは、
- 障害情報を一か所に集約する
- 影響を受けない障害内容についても通知を受ける
上記が必要と定め検討を開始しました。この記事ではAWSサービスの障害通知方法の検討とツールを利用した通知システムの構築についてご紹介します。
障害情報の把握
障害を通知するためには、まずは障害を把握する必要があります。把握の手段はいくらかありますが、以下が代表的なものかと思います。

AWSが提供するサービスの稼働状況を示すダッシュボードです。各リージョンおよび各サービス毎の稼働状況が示されています。それぞれにRSSフィードが配信されているため、確認したいリージョンまたはサービスのRSSフィードを購読して、サービスの状況を確認することが可能です。
AWSアカウントに紐づくかたちでサービス障害を記録してくれる機能です。バックエンドにAWS Health APIが使用されており過去90日間の障害情報が表示されます。ダッシュボードの閲覧にはAWSアカウントへのログインが必要となります。
- Twitter(非公式)
AWSが公式に提供しているものではないですが障害情報をツイートされています。東京リージョンに特化した @awsstatusjp と、リージョンを全体に広げた @awsstatusjp_all が存在するようです。
- DownDetector(非公式)
こちらもAWS非公式ですがSNSからの投稿内容を利用し各種サービスの状況を判断するWebサービスがあります。各種サービスにはAWSも含まれており、状態を確認することができます。
PHD利用時の課題
まず、上記の情報を通知に利用し、AWSだけで構成できる仕組みを考えました。
SHDを利用する場合、購読が必要になるRSSフィード数が多くなり、RSSフィードを登録した後のメンテナンス(追加・削除・確認等)に工数が掛かることが予想されたため、ここではPHDを利用した形での検討を進めました。
PHDはすでに構築されているダッシュボードを閲覧して障害状況を把握する方法の他に、AWS Cloudwatch Eventsと連携したアクションを取ることが出来ます。AWS Cloudwatch EventsのイベントトリガーをAWS Healthイベントに設定することで、PHDの更新に併せてターゲットを呼び出すことができます。これはドキュメントにも方法が紹介されています。このドキュメントではAWS Cloudwatch Eventsでイベントを受信する方法や、イベントを受信した後にAWS Chatbotを利用してビジネスチャットなどに障害情報を通知する方法が紹介されています。
ドキュメントを参考に構築したあとはしばらく状況を確認していましたが、障害発生しても通知がされないことがありました。確認を進めていくとHealth APIでは障害イベントの種類は2種類存在し、通知されるイベントはアカウント固有のイベントであるACCOUNT_SPECIFICのみであったことが分かりました。これはドキュメントにも記載があります。
Only AWS Health events that are specific to your AWS account are delivered to CloudWatch Events. For example, this can include events such as a required update to an Amazon EC2 instance and other scheduled change events that might affect your account and resources.Currently, you can't use CloudWatch Events to return public events from the Service Health Dashboard. Events from the Service Health Dashboard provide public information about the Regional availability of a service. These events aren't specific to AWS accounts, so they aren't delivered to CloudWatch Events.
上記引用にて記載されているとおり、今回通知されなかった障害イベントの種類はPUBLICとなっているようでした。
shd notifierの利用
記事冒頭で要件とした「影響を受けない障害内容についても通知を受ける」を満たすためには、PUBLICとなる障害イベントについても通知も受けたいところです。その場合には、AWS Health Tools - shd notifierの利用を検討することができます。こちらはAWSが提供しているツールで、SHDの更新情報を検知してAWS SNSやSlackなどのビジネスチャットに通知できるようにするものです。
shd-notifierはAWS Step Functions、AWS LambdaやAWS Cloudwatch Eventsを利用して構築されます。障害検知・通知をまとめて一つのワークフローとして定義して処理を行います。具体的には以下のような動作を行います。
- SHDへの定期的なポーリング
- 検知した障害に対しての定期的な状況確認
- 確認結果をSNS/ビジネスチャットへ投稿
デプロイは上述のGithubにCloudFormationで使用するテンプレートとLambda関数をデプロイするシェルが提供されているため、そちらを利用してデプロイする方法が簡単です。(弊社ではインフラ基盤をTerraformでコード管理しているため、一部を別途書き起こししています。)
結果
今回のデプロイの結果を、先日発生した障害内容から確認してみます。なお、投稿する先としてSlackを設定しています。
2021/05/07 03:16-04:43(JST) に AWS CloudFrontにおいてコンソール表示遅延の障害が発生しました。aws healthコマンドで確認すると以下の応答が返却されます。 eventScopeCodeの値がPUBLICとなっていることが確認できます。そのためこのAWSアカウントとしては本障害は公開イベント扱いとなります。
$ aws health describe-events --region us-east-1 | jq .events[]
:
{
"arn": "arn:aws:health:global::event/CLOUDFRONT/AWS_CLOUDFRONT_OPERATIONAL_ISSUE/AWS_CLOUDFRONT_OPERATIONAL_ISSUE_ZQLBL_1620324983",
"service": "CLOUDFRONT",
"eventTypeCode": "AWS_CLOUDFRONT_OPERATIONAL_ISSUE",
"eventTypeCategory": "issue",
"region": "global",
"startTime": "2021-05-07T03:16:23.386000+09:00",
"endTime": "2021-05-07T04:43:59.487000+09:00",
"lastUpdatedTime": "2021-05-07T04:44:00.233000+09:00",
"statusCode": "closed",
"eventScopeCode": "PUBLIC"
}
:
PUBLICとなっている通り弊社環境では幸いにも影響はありませんでした。通知状況を確認してみます。

障害発生後に初報が発報されたことが確認できました。[SHD AUTO]という文字がありますがこれは投稿時に付与することが出来るprefixで任意で設定することができます。
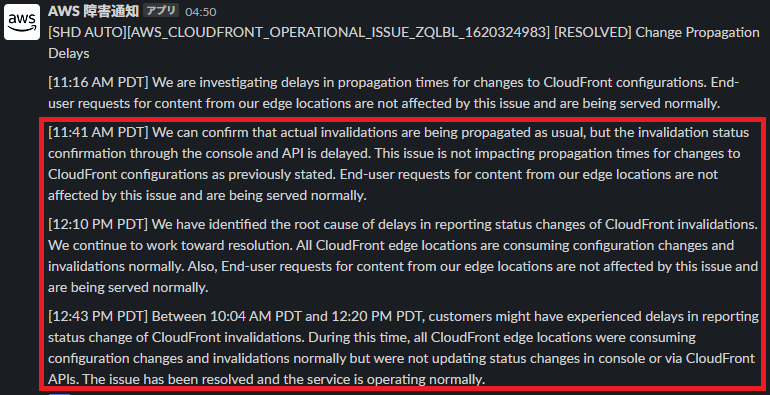
続いて、続報および終報が発報されました。12:43 PM(PDT)に正常に回復した旨が報告されています。
この続報/終報では、初報から時間が経過しており途中経過をまとめた報告となっています。これは投稿先への投稿間隔を比較的長めに設定したことによるものです。前述のGithubリポジトリにあるHealth-Event-Iterator-LambdaFn.pyで投稿間隔を調整可能です。
以上で、無事障害イベントの内容が通知されていることが確認できました。
まとめ
今回はAWSのサービス障害が発生した場合における、広い範囲での障害情報の収集および集約化についての手法の確認・構築を行いました。なお、AWS Step Functionsステートで動作するLambda関数はHealth APIを使用するため、AWSアカウントがビジネスアカウント以上である必要があります。ご注意ください。
今後は、
- 投稿内容のブラッシュアップ
- 障害対応自動化への応用検討
など引き続き改善を進め、障害対応の体制作りに貢献出来ればと考えています。